2019/2/2、2019/3/20改訂
これは統計処理プログラムの R を使っていて「ウキッ?→ウッホウッホ!」となったところを、わりとだらしなくメモしたもの。原始的なやり方で高級な関数を模倣しながら、その正体を探ったりする。用語の統一とか全然ねいです。ウソ書いてたらゴメンです。
R は CRAN (The Comprehensive R Archive Network) http://cran.r-project.org/ から入手でき、マニュアルもそこにある。
参考書は、Hadley Wickham 著 Advanced R がよかった。よい子はぜひよもう。
目次
多くのプログラミング言語では、数を 1 つだけ保持するためのデータ型があるが、 R には数を 1 つだけ保持するためのデータ型はない。
> x <- 10 > x [1] 10 > typeof(x) [1] "double"
のようなことができるから、「ちゃんと double 型があるじゃん」と思うかもしれないが
> y <- c(10, 20, 30) > y [1] 10 20 30 > typeof(y) [1] "double"
のように、3 つの数を並べてまとめたモノもやはり double 型である。
int 型、dougle型、complex 型, logical 型, character 型, raw 型のオブジェクトはみなこのようであって、言うならば R にはスカラーというものはなくて、これらがすべてがベクトルなのである。10 とか 10+10i とか TRUE とか "hello world" とかはすべて、たまたま長さが 1 だというだけで、どれもベクトルである。
ここでは raw 型はひとまずおいておくことにする。また、実数はたいがい double 型として作成されるので、int 型にお目にかかる機会は多くない。
なお、ベクトルの要素の数は、
> length(1) [1] 1 > length(c(1,2,3)) [1] 3
のようにすればわかる。
ついでに言っておくと、logical 型のベクトルが生成される典型的な例は次のようなもので、これは頻繁に使われる。
> y [1] 10 20 30 > y > 10 [1] FALSE TRUE TRUE
ベクトルの要素を取り出すには、1 から始まるインデックスを使うことができる。次は、長さが 3 の double 型のベクトルから最初の要素を取り出しているが、取り出したものも、やはり double 型のベクトルになる(長さは 1 である)。
> y [1] 10 20 30 > typeof(y) [1] "double" > y[1] [1] 10 > typeof(y[1]) [1] "double"
インデックスとしては、長さが 2 以上のdouble 型のベクトルも使うことができるし、また対象ベクトルと同じ長さを持つ logical 型のベクトルを用いることもできる。
> y[c(2,3)] [1] 20 30 > y[c(FALSE,TRUE,TRUE)] [1] 20 30
こうした logical 型のベクトルの長さが、対象ベクトルより短かいなら複製して何回も使われる。次は、100 までの奇数を出力しているところ。
> xx <-c(1:100) > xx[c(T,F)] [1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 [26] 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95 97 99
また、
> y[y>10] [1] 20 30
のようにして条件に合う要素を取り出すことができる。TRUE は T、FALSE は F と書いても同じ。
R のマニュアルは int 型、dougle型、complex 型, logical 型, character 型, raw 型のオブジェクトを、原子的(atomic)なベクトルと分類している。これらはその要素を取り出したときに常に同じ型のオブジェクトが得られる。
原子的(atomic)なベクトルは、このようにフラットな構造をしているので、ベクトルどうしをつなげるのには、
> c(c(1,2),c(3,4),5) [1] 1 2 3 4 5
のようにすればよい。
長さの足りないところに NA を詰め込んでベクトルの長さを伸ばしたいとき、案外簡単な方法がある。
> n <- c(1,2,3)というベクトルのおわりのほうに NA を詰め込んで、長さを 5 にするには、
> n[1:5] [1] 1 2 3 NA NAでよい。
原子的ベクトルに対し、包括的ベクトルと言えるのがリストである。リストはいかなる型のオブジェクトもその要素として持つことができ、リスト自体は常にlist型である。
R のモデルとなった S では「原子的」や「ベクトル」の定義が違うけれども、このページでは R の用語の使い方でいきたい。
> L<- list(c(10,20,30),c("ten","twenty","thirty"))
> L
[[1]]
[1] 10 20 30
[[2]]
[1] "ten" "twenty" "thirty"
> typeof(L)
[1] "list"
上の例で L は 2 つの要素 c(10,20,30) と c("ten","twenty","thirty") を持つものであるから、L の長さは 2 である。
> length(L) [1] 2
[[ ]] とインデックスを用いて、リストから要素を取り出すことができる。
> L<- list(c(10,20,30),c("ten","twenty","thirty"))
> L[[1]]
[1] 10 20 30
> typeof[[1]]
[1] "double"
[[ ]] でなく [] を用いると、リストから取り出したものを新たなリストにしたものが得られる。[[ ]] と [] はよく区別しなければならない。
> L[1] [[1]] [1] 10 20 30 > typeof(L[1]) [1] "list"
存在しないインデックス番号で list に要素を代入すると、NULL が詰め込まれる。たとえば、長さが 3 のリスト li があったとき、li[5] に値を入れると li[4] に NULL が詰め込まれる。
要素を追加してリストを伸張するには、リストもベクトルの一種であることを思い出せば、たんに c を使ってこれができることがわかる。次は、1,2,3 を要素をとして持つリストを長さ 1 つぶん伸張したリストを得ている。
> li <- list(1,2,3) > c(li,4) [[1]] [1] 1 [[2]] [1] 2 [[3]] [1] 3 [[4]] [1] 4
リストの合併も同じである。次の例を見ると、リストの各要素の中身を壊すことなく合併できていることがわかる。
> li <- list(c(1,2),c(3,4)) > li2 <- list(c(5,6),c(7,8)) > c(li,li2) [[1]] [1] 1 2 [[2]] [1] 3 4 [[3]] [1] 5 6 [[4]] [1] 7 8
R は、けっこう積極的に暗黙のうちに型変換してくる。明示的に型変換をして新たなオブジェクトを作成するには、「as.型名」という関数が型ごとに用意されている。
> as.character(10) [1] "10"
実数だと double 型のほかに int 型があるが、使う機会はそう多くない。そのうえ、必要に応じて暗黙の型変換が起こるから、たいていの場合は気にしなくてよい。
> typeof(as.integer(10)) [1] "integer"
統計処理を得意とするだけに R には欠損値を示す NA (Not Available)というオブジェクトがある。これは、logical 型の NA や double 型の NA や、character 型の NA があって、プリントすると同じだが、区別して使える。もっとも、きちんとやらなくても暗黙の型変換が起こることが多いから、そう心配する必要はない。
> as.logical(NA) [1] NA > as.double(NA) [1] NA > as.character(NA) [1] NA > typeof(as.logical(NA)) [1] "logical" > typeof(as.double(NA)) [1] "double" > typeof(as.character(NA)) [1] "character"
どの R オブジェクトも、3 系統の「型」を持つ。それぞれ typeof(), mode(), storage.mode() によって得ることができる。ふつう「型」といったときは typeof() か mode() の返すものである。後者は R のモデルとなった S に由来する。typeof() の型は double と integer を区別して報告するが、mode() はどちらも numeric と報告する。
以下の表は、よく目につくオブジェクトが何型なのかを 3 つの系統で表したものだ。
なお、型とクラスの関係は S3 と呼ばれるクラスの規格と、S4 と呼ばれるクラスの規格(R はこれらの 2 種類のクラスを共存させている)で話が別になる。S3 の場合は、任意の型のオブジェクトを任意のクラスのメンバーにすることが可能で、クラス名と型名は独立したものである。S4 の場合は、typeof(), mode(), storage.mode() のいずれで調べても型名が "S4" となる。ちなみに、あるオブジェクトが S3 か S4 かどちらでもないかを見分けるには、is.object() と isS4() を使う。S3 クラスもしくは S4 クラスのメンバーなら、is.object() が TRUE となる。S4 クラスの場合は、isS4() も TRUE となる。
.Machine というリストがある。私の環境でこれを見ると
> .Machine (前略) $double.xmin [1] 2.225074e-308 $double.xmax [1] 1.797693e+308 (中略) $integer.max [1] 2147483647 (後略)
になっている。意味するところは、help(.Machine) 参照。
私の環境で double の範囲を超えた数を扱おうとした例。
> 1.797693e+308 [1] 1.797693e+308 > 1.797694e+308 [1] Inf > -1.797693e+308 [1] -1.797693e+308 > -1.797694e+308 [1] -Inf
Inf を含む除算をすると、次のようになる。
> typeof(Inf) [1] "double" > Inf-Inf [1] NaN > Inf/Inf [1] NaN > typeof(NaN) [1] "double"
NaN は「数でない」("Not a Number")の意。
integer 型では
> as.integer(2147483648) [1] NA 警告メッセージ: NAs introduced by coercion to integer range > as.integer(-2147483647) [1] -2147483647 > as.integer(-2147483648) [1] NA 警告メッセージ: NAs introduced by coercion to integer range
R のオブジェクトは属性名と属性値を与えることができる。オブジェクトに特定の属性値を与える関数を使うか、より一般には次のように行う。
> x<-1 > attr(x,"foo")<-"bar" > attr(x,"foo") [1] "bar"
与えられたすべての属性を調べるには、
> attributes(x) $foo [1] "bar"
のようにすればよい。
いろいろなことを一気にやってくれる高級な関数は、暗黙のうちにさまざまな属性を設定することが多い。
すべてのオブジェクトは型属性と長さ属性を持つと考えることができ、これらは intringic(生来的)な属性と呼ばれることがある。
オブジェクトがどういう属性を持っているのかだけを知りたいような場合、names(attributes(x)) とするとよい。attributes (x) はオブジェクト x のすべての属性の属性値をまとめたリストに返すが、このリストの名札属性には属性名がセットされているからだ。
配列(array)の正体は、次元属性(dim)を持ったベクトルのことである。行列(matrix)はその特殊なもので 2 次元の配列である。
> mat <- c(10,20,30,40,50,60)
> dim(mat)<-c(2,3)
> mat
[,1] [,2] [,3]
[1,] 10 30 50
[2,] 20 40 60
上の例は、まず長さ 6 の numeric 型のベクトルを作成し、それに次元属性(dim)を与え、2行3列の行列を作成している。
1 行目からでなく、1 列目から埋められていくことに注意。これが気に入らなければ、aperm という関数を使って、次元を任意に取り替えることができる。aperm で行列の転置をやるなら、
> aperm(mat,c(2,1))
[,1] [,2]
[1,] 10 20
[2,] 30 40
[3,] 50 60
である。ここで、c(2,1) というのは、置換(permutation)を表している。つまり、1番目の次元を2番目に、2番目の次元を1番目に移すことを表している。もしこれを c(1,2) とすると、1番目の次元を1番目に、2番目の次元を2番目に移した結果何も変わらない。
2x2 行列を転置するだけなら、t() という関数がある。
行列を作るのに matrix 関数を使うこともできる。次の 2 つは上で作成した行列 mat と同じものを作る。
> mat <- matrix(seq(10,60,by=10), nrow=4) > mat <- matrix(seq(10,60,by=10), ncol=3)
(注) ?seq によると seq(m,n) や m:n で生成したベクトルの型は integer かもしれないし double かもしれない。型に依存する使い方をするのは危険。
さて、あらたに次元属性(dim)を与えたからといっても、。いま作成した mat は numeric型だし、長さ(length)は 6 である。次の例はこれを確認している。
> typeof(mat) [1] "double" > length(mat) [1] 6 > is.matrix(mat) [1] TRUE
行列はベクトルに過ぎないので、添字による要素へのアクセスも従来通り可能であるが、
> mat[4] [1] 40
dim 属性を与えたことにより行番号列番号を使ったアクセスも可能になる。
> mat[2,2] [1] 40
行と列のインデックスにより、特定の行や列を取り出すことも可能。
> mat[2,] [1] 20 40 60 > mat[,2] [1] 30 40
double や complex 型の行列は、和・差・定数倍などが定義されている。
> mat+mat
[,1] [,2] [,3]
[1,] 20 60 100
[2,] 40 80 120
> mat-mat
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
> 2*mat
[,1] [,2] [,3]
[1,] 20 60 100
[2,] 40 80 120
行列どうしの積は、
> mat
[,1] [,2] [,3]
[1,] 10 30 50
[2,] 20 40 60
> mat2<-c(1,2,3)
> dim(mat2)<-c(3,1)
> mat2
[,1]
[1,] 1
[2,] 2
[3,] 3
> mat %*% mat2
[,1]
[1,] 220
[2,] 280
こんな具合。
R ではリストもベクトルの一種である。ただ原子ベクトルではないというだけの話だ。というわけで、list 型のオブジェクトにも dim 属性を加えて配列(そしてその 2 次元版の行列)を作ることもできる。ただ、これをやる場面はそうそうないと思う。
> lmat <- list(1,"a",TRUE, NULL)
> dim(lmat) <- c(2,2)
> lmat
[,1] [,2]
[1,] 1 TRUE
[2,] "a" NULL
> typeof(lmat)
[1] "list"
> is.matrix(lmat)
[1] TRUE
list(c("ten", "twenty", "thirty"), c(10, 20, 30))
のように、同じ長さのベクトルをリストにまとめたものは、行列ではない。
ベクトルに名札(names)属性を付加すると、各要素に名前をつけることができる。
> a <- c(1, 2, 3)
> names(a) <- c("one", "two", "three")
こうしておくと、名前でベクトルの要素にアクセスできる。
> a["two"] two 2
ベクトル作成時に、名札をつけてしまうこともできる。
> a <- c(one=1, two=2, three=3)
> a
one two three
1 2 3
行列の行や列に名前をつけて、要素に行名、列名でアクセスできれば便利である。行列(などの配列)に、"dimnames" という属性を与え、その値に行名ベクトル、列名ベクトルからなるリストを与えればこれが実現できる。たとえば、
> mat <- c(11,21,12,22,13,23)
> dim(mat) <- c(2,3)
> mat
[,1] [,2] [,3]
[1,] 11 12 13
[2,] 21 22 23
という行列に対して
> attr(mat, "dimnames") <- list(c("row1","row2"),c("col1","col2","col3"))
> mat
col1 col2 col3
row1 11 12 13
row2 21 22 23
のようにすることができる。
dimnames()<-, rownames()<-, colnames()<- などは、"dimnames" 属性をセットするのに使える関数である。
これで、行名・列名で行列の要素にアクセスできるようになった。
> mat["row1",] col1 col2 col3 11 12 13 > mat[,"col1"] row1 row2 11 21 > mat["row1","col1"] [1] 11
R ではリストも(原子的ではないが)ベクトルの一種であり、これに対しても同じように名札属性をつけることができる。
> mylist <- list(c(1,2), c("one","two"))
> names(mylist) <- c("Numbers", "Characters")
名札でリストの要素にアクセスしてみる。
> mylist[["Characters"]] [1] "one" "two"
これは
> mylist$Characters [1] "one" "two"
としてもよい。
リスト作成時に、いっしょに名札をつけることもできる。
> mylist <- list(Numbers=c(1,2), Characters=c("one","two"))
> mylist[["Characters"]]
[1] "one" "two"
リストは各要素の長さが同じであっても、行列のようには列名をつけることができない。それは、data.frame と呼ばれる構造によって実現できる。
水準属性(levels)をセットしても、オブジェクトのクラスを "factor" にしておかないと、あまりありがた味がない。なので、factor の項で説明。
環境というのは、名前とオブジェクトを対応させる表の役目を果たすもので、環境自体も environment という型(type)のオブジェクトである。どの環境を使うかで、その名前がどのオブジェクトを指すかが変わってくる。
まず、env1 という環境を作成してみる。環境はどれも親環境というのを持っているが、ここでは emptyenv() つまり空っぽの環境を親にして env1 を作ってみよう。
> env1 <- new.env(emptyenv())
この env1 は、まだ何ら名前とオブジェクトの対応関係を持たないできたての環境である。したがって、下のようにして、この環境がもつ名前とオブジェクトの対応を調べてみても、何も報告されない。
> ls.str(env1)
with を用い、env1 環境のもとで x に 10 をバインドしてみる。
with(env1, x <- 10)
たしかに、env1 において x は 10 になっている。
with(env1, x) [1] 10
env1 の中で新しい環境を作成し、これに env2 と名づける。env1 を作るときは親環境を明示的に指定したが、今回はこの指定を省略している。
env2 <- with(env1, { new.env() })
env2 の中で x を評価してみる。
> with(env2,x) [1] 10
env2 で定義していない x の値が得られた。
もちろん、env2 じたいの中で x に 10 がバインドされているわけではない。
> env2$x NULL
env1 中で親環境を指定しないまま env2 を作ったために、2 つの環境間に親子関係ができたのである。その結果、env2 から env1 の内容が見えるようにになったのである。
なお、with(env2,x) や get("x", envir=env2) は env2 から見えるものであれば、それが先祖でバインドされたものであろうと報告するが、env2[["x"]] や env2$x は env2 自体の中でバインドされたものだけを報告する。
親子関係を確認してみる。
> identical(env1, parent.env(env2)) [1] TRUE
注 その名によって悪名高い parent.frame 関数は、この話の流れとは関係のないものである。
子環境で何をしようと親環境に影響はないから、env2 で x に 20 をバインドしても、env1 の x は 10 のままだ。
> with(env2, x <- 20) > with(env1, x) [1] 10 > with(env2, x) [1] 20
environment という関数は、引数を省略すると現在の環境を返す。R を立ち上げ、対話環境で何も考えずに使うときの環境を調べてみる。
> environment() <environment: R_GlobalEnv>
これはグローバル環境と呼ばれるものだ。
空環境(empty environment)の子がベース環境(base environment)で、それに library() や require() でどんどん子孫環境ができていった先の子孫としてグローバル環境(global environment)がある。
> emptyenv() <environment: R_EmptyEnv> #空環境 > baseenv() <environment: base> #ベース環境 > parent.env(baseenv()) #ベース環境の親は <environment: R_EmptyEnv> #空環境である > search() #グローバル環境のすべての親をリストすると [1] ".GlobalEnv" "package:stats" "package:graphics" [4] "package:grDevices" "package:utils" "package:datasets" [7] "package:methods" "Autoloads" "package:base"
最後にリストアップしたグローバル環境の親たちのうち、Autoloads というのはセッションの保存に使うやつだ。このリストから環境そのもの(environment型のオブジェクト)を得るには、as.environment 関数を使う。
> typeof(as.environment("Autoloads"))
[1] "environment"
environment という関数は、引数を省略すると現在の環境を返す。これを関数定義内に書き、f にバインドする。
f <- function() {
environment()
}
この関数 f を何回か実行してみると、
> f() <environment: 0x1b7afd0> > f() <environment: 0x1b7ac50> > f() <environment: 0x1b7bff8>
毎回、異なる環境が報告される。この環境たちは関数が実行されるときに作られる一時的な環境たちで、実行環境(execution environment)と呼ばれる。
実行環境は関数が実行を終えると消えてしまうから、もし下のように実行環境で x に 10 をバインドしても、この関係は実行環境の消滅とともになくなってしまう。
function () {
x <- 10
}
そこで、実行環境に名前をつけ、あとでアクセスできるようにしてみる。
> f2 <- function() {
x <- 10
environment()
}
> ex <- f2()
こうすると、実行環境は自分を参照するオブジェクトが存在するおかげで、関数が実行を終えても消滅せず生きながらえる。
> ex$x [1] 10
関数の実行環境の親環境は、それが定義されたときの環境になる。実行環境そのものは関数が実行されるたびに作られるけれども、親環境はいつでも変わらない。さきほど私は f2 をグローバル環境で作成したから、実行環境の親環境はグローバル環境になっている。
> parent.env(f2()) <environment: R_GlobalEnv>
もっとも、実行時より前に実行環境の親環境は決まっているわけだから、親環境を知るためには必ずしも関数を実行する必要はない。environment 関数の引数に関数を与えると、その関数の「実行環境の親環境となる環境」がわかる。
> environment(f2) <environment: R_GlobalEnv>
この、「実行環境の親環境となる環境」を、その関数のクロージング環境(closing environment)という。
次の例は、x の値を実行環境から得て、y の値をクロージング環境(この場合はグローバル環境がそれに当たる)から得て返している例である。
> y <- "I'm here in global environment."
> f3 <- function(){
x <- "I'm here in execution environment"
print(x)
print(y)
}
> f3()
[1] "I'm here in execution environment"
[1] "I'm here in global environment."
environment 関数は、クロージング環境を知るだけでなく、それをセットするのにも使える。下の例は、関数 f3 のクロージング環境をグローバル環境からベース環境につけ代えたおかげで、y の値を得ることに失敗している。
> environment(f3) <- baseenv() > f3() [1] "I'm here in execution environment" print(y) でエラー: オブジェクト 'y' がありません
一般に、関数と関数が定義された環境を併せたモノをクロージャーと言うようである(概念をそう言うのか構造をそう言うのか、しらんけど)。
R の場合、関数(mode 関数で調べると "function" と報告されるオブジェクト)を、typeof 関数で調べると "builtin" とか "closure" とかになる。sum のような関数はクロージング環境が NULL になっていて "builtin" 型の関数である。これに比べて、さっき作った f3 のような関数は NULL 以外のクロージング環境を持っていて "closure" 型である。
「『関数を返す関数」を作って、m という名前で参照できるようにしてみる。
> m <- function(){
function() {
(省略)
}
}
この関数 m を実行し、その戻り値を n という名前で参照することにする。
> n <- m()
すると、関数 m の実行環境が、関数 n のクロージング環境になる。
関数のクロージング環境は、関数が存在する限り存在し続ける。そのため上のような場合、本来すぐ消えてしまうはずの関数 m の実行環境が、関数 n のクロージング環境として生きながらえることになる。
例を見てみる。次の p は、「決まった文字列を引数に付加して出力する関数」を作成する関数である。
> p <- function(x) {
function(y){
paste(y,x)
}
}
次は、この関数 p を用いて "san" を付加する関数 san や、"kun" を付加する関数 kun を作成している。
> san <- p("san")
> kun <- p("kun")
次は、こうして作った関数 san や kun を使っている様子。
> san("sazae")
[1] "sazae san"
> kun("masuo")
[1] "masuo kun"
文字列 "san" や "kun" が保管されている場所は、関数 san や関数 kun の本体ではなく、そのクロージング環境である。
> ls.str(environment(san)) x : chr "san" > ls.str(environment(kun)) x : chr "kun"
したがって、たとえば関数 san のクロージング環境で定義されている x の値を変えると、関数 san の挙動が変わる。
> environment(san)$x <- "chan"
> san("tara")
[1] "tara chan"
クロージング環境は関数から読めるばかりでなく、関数からそれにアクセスして変更を加えることもできる。これを利用して、呼び出されるたびにカウンターに 1 を加えてその値を報告する関数を作成してみる。
引数として整数を与えて下の関数 c を実行すると、その値で初期化したカウンターを持つ関数(下の例では c1 関数)を返す。このカウンター関数は、呼び出されるたびに、自らのクロージング環境に保管されているカウンターをすすめ、その値を報告する。
> c <- function(x) {
function() {
assign("x",x+1,envir=parent.env(environment()))
x
}
}
> c1<-c(0)
> c1()
[1] 1
> c1()
[1] 2
> c1()
[1] 3
関数 c1 は自分のためのクロージング環境を背負っているから、呼び出し元の環境に影響されず同じように働く。 次は、base environment から c1 関数を呼び出してカウントを続けているさま。
> with(baseenv(),do.call(globalenv()$c1,list())) [1] 4
関数定義中で parent.frame() を使うと、どの環境から呼び出されたのか(calling environment)がわかる。これを用いれば、関数の中から呼び出し元の環境を知ることが可能である。
自分の呼び出し元環境における x が指すものを報告する関数を作ってみる。
> x_here <- function () {
get("x", envir=parent.frame())
}
グローバル環境で x が 10 を指すようにし、また、new_env という新しい環境を作成して、その中では x が 100 を指すようにする。
> x <- 10 > new_env <- new.env() > new_env$x <- 100
それぞれの環境から(グローバル環境で定義されている x_href という名前をたどって)、さきほど作成した関数を実行してみる。
> x_here() [1] 10 > with(new_env, do.call(globalenv()$x_here,list())) [1] 100
こうした関数の仲間は、色々似たものがあるので、2 つだけ見ておく。
R の関数の多くは、長さが 1 より大きなベクトルを引数にすることができるので、原子ベクトルのようなものの各要素に対して関数を繰り返し適用するのは容易なことだ。
> sqrt(c(1,2,3)) [1] 1.000000 1.414214 1.732051
しかし、それだけでは済まないことも多い。たとえば
> a <- list(c(1,2,3),c(4,5,6),c(1,1,1)) > a [[1]] [1] 1 2 3 [[2]] [1] 4 5 6 [[3]] [1] 1 1 1
において、リストの要素である 3 つのベクトルについてそれぞれ合計を求めたいとする。そのためには sum 関数を 3 回適用するための仕組みが必要になる。このとき、for ループはできる限り書かないのが R らしいやり方だろう。
lapply 関数は、第一引数で指定されたリスト各要素に対して、第二引数で指定した関数を実行し、結果をリストにまとめて返す。
> lapply(a, sum) [[1]] [1] 6 [[2]] [1] 15 [[3]] [1] 3
次にさきほどのリスト a 各要素の先頭要素を選び出すことを考えてみる。行列ならば a[1,]=1 などで c(TRUE, FALSE, TRUE) という logical 型のベクトルが得ることができるが、この場合はそれほど簡単にはいかない。ベクトルを与えられると先頭要素を選び出すという関数を自作すると、次のようにしてこれが実現できる。
> lapply(a, function(x) x[1] ) [[1]] [1] 1 [[2]] [1] 4 [[3]] [1] 1
もうひとつ利用例を。NA を詰め込んでリストの要素の長さをそろえたいということが、しばしばある。たとえば、
> li <- list(1,c(2,3),c(4,5,6)) > li [[1]] [1] 1 [[2]] [1] 2 3 [[3]] [1] 4 5 6
というリストの各要素の長さはそれぞれ、1, 2, 3 であり、そろっていない。長さのたりないところに NA を詰めて、どの要素も長さを 3 にしてみる。
> li <- lapply(li,function(x)x[1:3]) > li [[1]] [1] 1 NA NA [[2]] [1] 2 3 NA [[3]] [1] 4 5 6
lapply に似たものに、sapply と vapply がある。sapply は lapply のラッパー。replicate はさらにそのラッパー。vapply は戻り値のタイプをあらかじめ指定するらしいけど、よく知らない。
tapply は類別データの値によって、ベクトルをいくつかに切り分け、それに関数を適用する。たとえば、
> animal <- c("cat", "dog", "cat")
> points <- c(10, 20, 30)
というデータがあったとする。ポイントを cat と dog 別々に集計したい。
> tapply(points, animal, sum) cat dog 40 20
上で tapply 関数が戻しているのは、double 型のベクトルで、名札属性に "cat" とか "dog" が入っているもの。
tapply でクロス集計をすることもできる。
3 人に好きな食べものと、好きな飲み物を尋ねたので、人数をクロス集計してみたい。
というデータを
> food <- c("sushi", "curry", "curry", "sushi")
> drink <- c("tea", "tea", "coffee", "tea")
のようにベクトルにしてみる。それから
> cross <- tapply(1:4, list(food, drink) , length)
のように集計する。tapply の第一引数は、サンプル数と同じ長さのベクトルであれば何でもよい。これは数を数えるために使うだけだからだ。第二引数は、クロス集計をするための 2 つのキーがリストとして指定されている。length はグループごとに分割された第一引数のベクトルを数えるために指定したものである。結果は
> cross
coffee tea
curry 1 1
sushi NA 2
となる。この cross というオブジェクトの正体は、 dim 属性に c(2,2) を持ったinteger 型の行列である。
「カレーと茶が好きなのは何番目の人だろう」という疑問に答えるには、
> curry_tea <- tapply(1:length(food), food=="curry" & drink=="tea" , c) > curry_tea $`FALSE` [1] 1 3 4 $`TRUE` [1] 2
2 番目のサンプルであるとわかる。この curry_tea というオブジェクトの正体は、list 型のオブジェクトである。
なお、グループ分けに使うベクトルは factor クラス(後述)になっていてもかまわない。
> animal <- c("dog","cat","cat")
> animalf <- factor(animal)
> points <- c(10, 20, 30)
> tapply(points, animalf, sum)
cat dog
50 10
tapply には by というラッパーがある。
aggregate という関数でも同じようなことができる。第一引数に与えられたベクトルを、by に指定されたリストの各要素(それぞれベクトル)によっていくつかにグループ分けして、グループごとに FUN で指定された関数を適用して統計量(総和とか平均とか)を求めたりする。
> animal <- c("dog","cat","cat")
> animalf <- factor(animal)
> points <- c(10, 20, 30)
> aggregate(points, by=list(animalf), FUN=sum)
Group.1 x
1 cat 50
2 dog 10
なお、by に 2 つ以上のベクトルを持つリストを与えることで、クロス集計もできる。
S3 クラスと呼ばれるのは古いタイプのクラスで、非公式クラスと言われることもある。厳格さにおいて S4 クラスに劣りはするが、新しい R もこれをサポートし続けている。時刻を扱うためのクラスや、data.frame クラスは S3 クラスである。
たとえば character 型のベクトルを作成する。
> sazae <- "Sazae" > masuo <- "Masuo"
これに、"class" という属性を付加し、その属性値をセットする。
> class(sazae)<-"girl" > class(masuo)<-"boy"
これで S3 クラスに属するオブジェクトが完成である。あらかじめクラスが設計されている必要はない。ようするに、S3 クラスに属するオブジェクトというのは、"class" 属性がセットされているというだけで、そのほかは一般のオブジェクトと変わりがない。この例では型が character だったが、これは何型でもよい。
ここまでの二段階を、次のようにして一気にやることもできる。
> sazae <- structure("sazae", class = "girl")
"class" 属性がセットされたオブジェクトかどうかは is.object() 関数で調べることができる。
> is.object(sazae) [1] TRUE
コンストラクタ関数を手作りしておくと便利な場合も多い。
> girl <- function(x) {
if (!is.character(x)) stop("must be character type")
structure(x, class = "girl")
}
> boy <- function(x) {
if (!is.character(x)) stop("must be character type")
structure(x, class = "boy")
}
さて、次にメソッドを作る。
まず generic 関数というものを作成する。これはいつも次のようなものでよい。
> respect <- function (x) {
UseMethod("respect")
}
generic 関数は引数に与えられたオブジェクトのクラスを見分けて、クラスごとに別々の関数に処理を任せる働きをする(このはたらきを method dispatch という)。
実際の処理を担当する関数は、「generic関数の名前.クラス名」という名前で作成する。
> respect.boy <- function (x) {
paste (x, "kun")
}
> respect.girl <- function (x) {
paste (x, "san")
}
では、使ってみよう。generic 関数の引数に各クラスに属するオブジェクトを与えればよい。
> respect(sazae) [1] "Huguta Sazae san" > respect(masuo) [1] "Huguta Masuo kun"
ちなみに methods という関数は、generic 関数を引数にとり、それが処理を任せる関数をすべてリストする。(引数が S4 クラスであるなら、それに属するメソッドのリストを得る)。
> methods(respect) [1] respect.boy respect.girl
先ほど generic 関数を
> respect <- function (x) {
UseMethod("respect")
}
のように書いた。復習してみると、この generic 関数を respect(sazae) と打って呼び出すと、sazae の処理は respect.girl に任されることになる。この respect.girl の respect の部分は、generic 関数中にある UseMethod("respect") の "respect" に由来するのであるが、一方で girl の部分は、generic 関数に引数として与えられたオブジェクト sazae のクラス名に由来する。
じつは、UseMethod は第二引数として任意のオブジェクトを与えることができて、たとえば UseMethod("respect", masuo) などとしておくと、respect(sazae) を実行した結果、処理は respect.boy に任される。masuo のクラス名が boy だからである。
> respect <- function (x) { # generic 関数を上書き
UseMethod("respect", masuo)
}
> respect(sazae)
[1] "Sazae kun"
つまり、最初に行った generic 関数 respect の定義は
> respect <- function (x) { # generic 関数を再び上書き
UseMethod("respect", x)
}
> respect(sazae)
[1] "sazae san"
ということであったわけだ。
sazae や masuo といったオブジェクトの class 名は 1 つでなくてもかまわない。たとえば
> tara <- structure("tara", class = c("child","boy"))
というオブジェクト tara を作成しておく。ここでまだ respect.child というメソッドは定義されていないとすると、
> respect(tara) [1] "tara kun"
のようになる。generic 関数 respect は、オブジェクトに複数指定されたクラス名を頭から見ていき、最初に見つかった「そのクラスに対応したメソッド」に処理を任せるのである。ここでは respect.child というメソッドが定義されていないから、respect.boy に処理が任されたのだ。
まるで、child クラスがそのスーパー・クラスである boy クラスで定義されたメソッド respect を上書きしていないので、スーパー・クラスで定義されたメソッドが使われたような雰囲気である。
もっとも、ここに wakame という別のオブジェクトを作成して、
> wakame <- structure("wakame", class = c("child","girl"))
のように定義しておくと、
> respect(wakame) [1] "wakame san"
のようになるわけだから、これを見ると child クラスは boy クラスでなくて girl クラスを継承しているように見えるかもしれない。
さて、もちろんどちらの場合も、respect.child というメソッドが定義されていたら結果は違ってくる。
もし respect.child が
> respect.child <- function(x) {
"(kodomo)"
}
のように定義されていたら、
> respect(tara) [1] "(kodomo)" > respect(wakame) [1] "(kodomo)"
のようになる。つまり、tara と wakame の 2 番目のクラス名である "boy" や "girl" は無視されるわけだ。これは、当然であまり面白くない。
しかしながら、である——もし respect.child メソッドが
> respect.child <- function(x) {
paste("(kodomo)",NextMethod())
}
のように定義してあると、面白いことが起こる。
> respect(tara) [1] "(kodomo) tara kun" > respect(wakame) [1] "(kodomo) wakame san"
どちらの出力でも "(kodomo)" というのは、respect.child 関数中に書いた "(kodomo)" に由来する。しかし、その後に貼り付けられた "tara kun" や "wakame san" は、respect.child 関数中から respect.boy や respect.girl を呼び出されてできたものだ。NextMethod() は自分の兄弟メソッドを呼び出す仕組みなのである。
はじめから R で定義されているようなクラスでは、そのクラスについてのドキュメントが用意されている場合が多い。たとえば、data.frame クラスについて知りたいなら、
> class?data.frame
のようにすると、それを表示することができる。
> a <- c("cat", "dog", "dog")
というベクトルに出現する因子は、
> u <- unique(a) > u [1] "cat" "dog"
だけである。そこで、ベクトル a の各要素が、ベクトル u の何番目の要素と同じであるかを表す
> i <- match(a,u) > i [1] 1 2 2
というベクトル i を作り、必要に応じてこれを u というベクトルを使って解読することにしたい。
R でこれを行うためには、まず i の levels 属性に u をセットする。
> levels(i) <- u > i [1] 1 2 2 attr(,"levels") [1] "cat" "dog"
それから、クラス属性を "factor" にセットする。
> class(i) <- "factor"
すると、i がまるで元の a から変わっていないかのように表示される。
> i [1] cat dog dog Levels: cat dog
これは、print() 関数が、i のクラス名 "factor" を見分けて、print.factor() 関数に処理を任せたからである。print.factor() 関数は levels 属性の値を使って、整数のベクトルを character 型のベクトルに戻して表示したわけである。
print() に限らず、いろいろな関数が factor クラスのオブジェクトをうまく扱ってくれる。factor クラスのオブジェクトを処理するための関数としては、
> methods(class="factor") [1] Math Ops Summary [ [<- [6] [[ [[<- all.equal as.Date as.POSIXlt [11] as.character as.data.frame as.list as.logical as.vector [16] coerce droplevels format initialize is.na<- [21] length<- levels<- plot print relevel [26] relist rep show slotsFromS3 summary [31] xtfrm
のようなものがある。
ここには挙がっていないような関数もうまくやってくれることが多い。たとえば paste() は引数を as.character を通してから使うので、
> i [1] cat dog dog Levels: cat dog > ii <- paste(i, i) [1] "cat cat" "dog dog" "dog dog" > typeof(ii) [1] "character"
のようなことが可能である。
さて、これまでの例では、character 型のベクトルから factor クラスのオブジェクトを作ったが、数値型(integer, double, complex)のベクトルからも factor 型のオブジェクトを作ることはできる。
いずれにしても、factor クラスのオブジェクトに対して as.character() のたぐいの関数を使うと、たんなるベクトルに戻すことができる。
> as.character(i) [1] "cat" "dog" "dog"
factor クラスのオブジェクトを作成する作業を一つの関数でやってくれるのが factor() である。
> a <- c("cat", "dog", "dog")
> fa <- factor(a)
> fa
[1] cat dog dog
Levels: cat dog
factor クラスのオブジェクトに、要素の追加・代入ができることは一般のベクトルの場合と同様である。factor オブジェクトの本体は integer 型のベクトルであるが、次のように平然と文字列が代入できる。これは、 <- オペレーターが factor クラスのオブジェクトを特別扱いするからだ(注)。
> fa [1] dog cat cat Levels: cat dog > fa[4] <- "dog" > fa [1] dog cat cat dog Levels: cat dog
また、factor クラスのオブジェクトどうしについて、次のようなこともできる。
> f1 <- factor(c("dog","cat"))
> f2 <- factor(c("cat","cat"))
> f1[3:4]<-f2
> f1
[1] dog cat cat cat
Levels: cat dog
ただし、levels 属性の値となっているベクトル中にないものを代入しようとすると、エラーを表示し NA が入る。(ちなみに、NA は levels の値に現れていなくても代入できる)。
> fa[3] <- "monkey" 警告メッセージ: `[<-.factor`(`*tmp*`, 3, value = "monkey") で: invalid factor level, NA generated
こういう場合は、factor クラスのベクトルを、as.character()を使って character ベクトルに戻したのちに要素を追加し、再び factor クラスのオブジェクトを作るのが手っ取り早いと思う。(もちろん、levels 属性を編集してから代入すればいいし、便利なライブラリがあるかもしれない)。
data.frame() や、read.table() などはよく使われる関数だが、お任せでやると黙って factor クラスのオブジェクトを作成するので注意が必要だ(オプションで選択できる)。
注 仕組みを調べてみると、次のような感じだ。
> methods('[<-')
[1] [<-,data.frame-method [<-.Date [<-.POSIXct
[4] [<-.POSIXlt [<-.data.frame [<-.factor
[7] [<-.numeric_version [<-.raster* [<-.ts*
see '?methods' for accessing help and source code
> getAnywhere('[<-.factor')
A single object matching ‘[<-.factor’ was found
It was found in the following places
package:base
registered S3 method for [<- from namespace base
namespace:base
with value
function (x, ..., value)
{
lx <- levels(x)
cx <- oldClass(x)
if (is.factor(value))
value <- levels(value)[value]
m <- match(value, lx)
if (any(is.na(m) & !is.na(value)))
warning("invalid factor level, NA generated")
class(x) <- NULL
x[...] <- m
attr(x, "levels") <- lx
class(x) <- cx
x
}
<bytecode: 0x2d15b80>
<environment: namespace:base>
参考 https://stackoverflow.com/questions/19226816/how-can-i-view-the-source-code-for-a-function
データ・フレーム(data frame)の正体は list 型のオブジェクトある。そして、"class" 属性は data.frame の S3 オブジェクトだ。
べんきょうのため data.frame を手作りしてみる。
まず、リストを用意する。
> d <- list(c("a", "b", "c"), c(1,2,3))
> d
[[1]]
[1] "a" "b" "c"
[[2]]
[1] 1 2 3
class 名を "data.frame" にする。
> class(d) <- "data.frame"
まず、この状態でプリントしてみる。
> d NULL <0 行> (または長さ 0 の row.names)
まったく期待はずれだ。
ここで、リスト d の要素 c("a", "b", "c") と c(1,2,3) を 2 つの列として見たときの、行名にあたる名前をつけてみる。とはいっても、c("a", "b", "c") と c(1,2,3) それぞれの要素に names 属性を使って名前をつけるというわけではない。c("a", "b", "c") と c(1,2,3) に共通して持たせたい行名を、オブジェクト d の属性としてセットするのである。そのための属性名に "row.names" を使う。
> attr(d, "row.names") <- c("sample1", "sample2", "sample3")
これは、row.names(d) <- と書くこともできる。
一般のリストに row.names なんて属性をつけても、何も意味がない。しかし、オブジェクトがクラス data.frame に属する場合にはそうではない。
> d
NA NA
sample1 a 1
sample2 b 2
sample3 c 3
素敵な表にプリントしてくれた。
これは、print() というのが generic 関数なので、"data.frame" というクラス名を見て、処理を print.data.frame() に任せたからである。そのときに、row.names 属性がセットしてあることが利いてくるわけである。
列名が NA なのは残念なので、こちらにも名前をつけておく。これは、リスト d の要素に名前をつければいいので、たんに names 属性を使えばよい。
> names(d) <- c("variable1", "variable2")
> d
variable1 variable2
sample1 a 1
sample2 b 2
sample3 c 3
もちろん、sample1〜3、variable1〜2 を使って、このデータ・フレームの要素にアクセスできる。
行列とデータフレームは混同しやすいので、ちょっと整理しておく。
data.frame() という高級なコンストラクタ関数にリストを与えれば、data.frame オブジェクトができる。
> d <- list(c("a", "b", "c"), c(1,2,3))
> dfr <- data.frame(d)
> row.names(dfr)=c("sample1","sample2", "sample3")
> names(dfr)=c("variable1", "variable2")
> dfr
variable1 variable2
sample1 a 1
sample2 b 2
sample3 c 3
あるいは、要素を引数として直接与え
> data.frame(variable1=c("a", "b", "c"), variable2=c(1,2,3),
row.names=c("sample1","sample2","sample3"))
variable1 variable2
sample1 a 1
sample2 b 2
sample3 c 3
のようにする。c("a", "b", "c") や c(1,2,3) のところは、それらを指すシンボルを使うことのほうが多いと思う。
さて、しかしながら、われわれが手動で作成したデータフレーム d と、data.frame() で作成した dfr とには、若干違いがある。プリントすると違いがわからないが、前者で a,b,c の列が character ベクトルであるのに対して、後者のそれは、factor という S3 クラスに属すオブジェクトである。(factor 参照)。もし、data.frame() を使ってデータフレームを作るときに、類別データの列を素朴な character ベクトルのままにしておきたいのなら、data.frame() をするときに、オプショナルな引数として stringsAsFactors=FALSE としておく必要がある。
print() の他にも、data.frame に使える generic 関数がいろいろあるので、最後にそれらをリストアップしておく。
> methods(class="data.frame") [1] $ $<- Math Ops Summary [6] [ [<- [[ [[<- aggregate [11] anyDuplicated as.data.frame as.list as.matrix by [16] cbind coerce dim dimnames dimnames<- [21] droplevels duplicated edit format formula [26] head initialize is.na merge na.exclude [31] na.omit plot print prompt rbind [36] row.names row.names<- rowsum show slotsFromS3 [41] split split<- stack str subset [46] summary t tail transform unique [51] unstack within see '?methods' for accessing help and source code
そもそも日本語の「日本時間午前10時」というのは何を表しているのか。タイム・ゾーンとローカル・タイムが与えられているから、そこから協定世界時がわかるというのは、もちろんそうである。だが、それにもかかわらず、「日本時間午前10時」が何を表しているかということは、依然としてはっきりしないのである。
つまり、「日本時間午前10時」と言ったとき、それが「『午前10時』を日本時間で解釈したときに得られる、宇宙開闢以来その一瞬しかない特定の時間」のことなのか、あるいは、「『日本時間午前10時』という表記そのもの」のことなのか、わからないのだ。
もし前者であるなら、「日本時間午前10時」に対して「タイム・ゾーンを世界協定時に変える」ということは「世界協定時午前1時」を得ることになる。一方後者であるなら、「世界協定時午前10時」を得ることになる。
R の場合、「年月日時分秒」と「タイムゾーン」をいっしょにして保存するための POSIXlt というクラスがある。そして、ここでもわれわれは「これが何であるか」について 2 通りの見方をすることができる。POSIXlt クラスのオブジェクトは「年月日時分秒をタイムゾーンで解釈した結果あらわされる時刻」を表すためのオブジェクトなのか、それとも「年月日時分秒とタイムゾーンからなるただの表記」を収納するためのオブジェクトなのか。
結論じみたことを先に言うならば、POSIXlt クラスは、たんに年月日時分秒とタイムゾーンを併せた〈表記〉をリストの形で保存するためのクラスで、「そこに保存された年月日時分秒を、そこにいっしょに保存されているタイムゾーンを使うことによって時刻として解釈するかどうか」は、POSIXlt を扱う関数しだいである。
これに比べて、POSIXct は、時刻を一意的に表現する「unix 紀元(UTC 1970年1月1日午前0時0分0秒)からの経過秒」をあらわす実数を保存するクラスである。したがって、タイムゾーンによる解釈を必要とせず、このクラスのオブジェクトを時刻そのものと同一視してもさして不都合はない。
以下のメモでは便宜上、POSIXlt をただの〈表記〉と考え、POSIXct を〈時刻〉と同一視する。
まず、テキストから POSIXct を作成してみよう。
> ct <- as.POSIXct("2020/1/2 13:14:15", format="%Y/%m/%d %H:%M:%S", tz = "Japan")
この関数の意味するところは「第一引数の "2020/1/2 13:14:15" というテキストを "Japan" のタイム・ゾーンによって解釈して〈時刻〉すなわち POSIXct クラスのオブジェクトを得よ」である。
> typeof(ct) [1] "double" > as.numeric(ct) [1] 1577938455
困惑させられるのは、対話画面でたんに ct と打ち込んでリターンキーを押したときである。1577938455 と表示されると思いきや、実際は
> ct [1] "2020-01-02 13:14:15 JST"
となる。これは、print() 関数が ct のクラスが POSIXct であることを見分けて、print.POSIXct() 関数に処理を任せたからだ。print.POSIXct() 関数は、ct が保管している 1577938455 という unix 元年からの秒数をもとに、「"Japan" のタイムゾーンで解釈したら 1577938455 という時刻が求まるような年月日時分秒」を得て、それを画面に表示しているのである。
(注)タイムゾーンを指定するときに、国名を使って "Japan" のように指定するか、"JST" (Japan Standard Time) のように指定するか迷うが、私の環境で安全なのは "Japan" のほうらしい。プリントしたときに JST と表示されるからといって、タイムゾーンの指定のときに "JST" を使うと、私の使っている R は「そんな国知らん」ということで、黙って計算するときに協定世界時を使ってしまう。
さらに困惑するのは、print.POSIXct() は、どこから "Japan" を見つけてきたのか、という点である。ふつうに考えると、システムのタイムゾーンだが、じつはそうではない。POSIXct クラスのオブジェクトが、密かに "tzone" という属性を持っていて、その値が "Japan" だったのである。
> unclass(ct) [1] 1577938455 attr(,"tzone") [1] "Japan"
じっさい、この tzone 属性を "Hongkong"(香港)に代えてみると、ただオブジェクト名を打ち込んだときに
> test <- ct > attr(test, "tzone") <- "Hongkong" > test [1] "2020-01-02 12:14:15 HKT"
のようなことになる。"Japan" のタイムゾーンで解釈すると 13時 だったのが、1 時間遅れて 12時になっている。この 1 時間は日本と香港の時差ぶんだ。
それにしても、これはいったいどうしたことだろう。POSIXct は 1577938455 という実数だけ保持していれば任務は果せるのである。いつこっそりと timezone などという不要に思える属性を持ったのかというと、as.POSIXct() がこのオブジェクトを作ったときである。POSIXct オブジェクトに口をきかせるならば、「as.POSIXct() さんが俺を作ったときにはさあ、"Japan" のタイムゾーンを使ったそうなんだよ」というわけである。「お前なんのためにそんなことを覚えているんだ?」と全力で突っ込みたいところである。しかも、print.POSIXct() 関数はちゃっかりとそれを使って気を利かせたのだ。これについては「余計な気を利かせるお前もお前だよ」というのが私の感想だ。
ちなみに POSIXct クラスのオブジェクトが属性 tzone の値を持っていない場合、print.POSIXct() はシステムのタイムゾーンを用いて表示する。
いちおう、ct のクラスを調べてみると、
> is.object(ct) [1] TRUE > isS4(ct) [1] FALSE
となっていて、S3 クラスであることがわかる。そして、クラス名は
> class(ct) [1] "POSIXct" "POSIXt"
となっている。二番目にある POSIXt というのは、POSIXct と POSIXlt の共通するスーパークラスで、たとえば POSIXct と POSIXlt の差を求めるというようなときに使われるそうである。
さいごに、POSIXct クラスのためのメソッドをリストしておこう。
> methods(class="POSIXct") [1] Summary [ [<- [[ as.Date [6] as.POSIXlt as.data.frame as.list c coerce [11] format initialize mean print rep [16] show slotsFromS3 split summary weighted.mean [21] xtfrm
次にテキストから POSIXlt クラスのオブジェクトを作成してみる。
> lt <- as.POSIXlt("2020/1/2 13:14:15", format="%Y/%m/%d %H:%M:%S", tz = "Japan")
関数名が違うだけで、引数は as.POSIXct() のときと違わない。しかし、この関数の意味するところは「"1970/1/1 0:0:1" というテキストにタイム・ゾーン "Europe/London" の情報を加えて、新しく〈表記〉を作成せよ」である。
POSIXlt クラスのオブジェクトはリスト型であるので、その中身を直接覗いてみる。
> typeof(lt) [1] "list" > unlist(lt) sec min hour mday mon year wday yday isdst zone gmtoff "15" "14" "13" "2" "0" "120" "4" "1" "0" "JST" NA
year は 1900 年を 0 とした整数。mon は 1 月を 0 とした月。mday はその月の 1 日を 1 とした日。hour, min, sec はそれぞれ時分秒。wday は日曜日を 0 とした曜日。yday は 1 月 1 日を 0 とした年内日。isdst は夏時間かどうか(正は夏時間、負は夏時間でない、0 は不明)。zone はタイムゾーン。gmtoff は GMT(グリニッジ標準時)からのオフセット。正なら東半球、負なら西半球。不明なら NA。
もし、たんにこの lt を対話画面で打ち込んでリターンキーを押すと、
> lt [1] "2020-01-02 13:14:15 JST"
と表示されるが、これは unlist(lt) の要約になっている。
これは、print() 関数が lt のクラス名を読み取り、処理を print.POSIXlt() 関数に任せ、print.POSIXlt() 関数が lt の内容を要約して表示したものだ。これは、たんなる要約であるから、ここで表示されるタイムゾーンは、システムのタイムゾーンではなく、lt が持っている zone の値そのままだ。(今回はどちらも JST だったので、見分けられないけれど)
POSIXlt クラスのオブジェクトのためのメソッドをリストしておく。
> methods(class="POSIXlt") [1] Summary [ [<- anyNA as.Date [6] as.POSIXct as.data.frame as.double as.matrix c [11] coerce duplicated format initialize is.na [16] length mean names names<- print [21] rep show slotsFromS3 sort summary [26] unique weighted.mean xtfrm
as.POSIXlt() のもう一つの使い方は、POSIXct クラスのオブジェクトから POSIXlt クラスのオブジェクトを作成することだ。
# いったん POSIXct を作ってから
> ct <- as.POSIXct("2020/1/2 13:14:15", format="%Y/%m/%d %H:%M:%S", tz = "Japan")
# PISIXlt を作ってみる
> lt_hkg <- as.POSIXlt(ct, tz="Hongkong")
ここで as.POSIXlt 関数にやらせていることは、「与えられた〈時刻〉から『"Hongkong" のタイムゾーンで解釈すると、その時刻が求まるような年月日時分秒』を得て、これに "Hongkong" のタイムゾーン名を添えて、新しい〈表記〉を作成せよ」だ。
> unlist(lt_hkg)
sec min hour mday mon year wday yday isdst zone
"15" "14" "12" "2" "0" "120" "4" "1" "0" "HKT"
gmtoff
"28800"
できたオブジェクトの中身を見てみると、もともと日本時間で 13 時を指定したところが正午になっている。結果として、「Q. 日本が 13:14 のとき、香港は何時何分でしょう」「A. 12:14 です」という変換が実現している。
まず、
> lt <- as.POSIXlt("2020/1/2 13:14:15", format="%Y/%m/%d %H:%M:%S", tz = "Japan")
のようにして lt という POSIXlt オブジェクトを作成しておく。そのうえで、
> ct2 <- as.POSIXct(lt)
のように、POSIXct オブジェクトを作ってみる。POSIXlt のリスト中に保存されている年月日時分秒を、やはり POSIXlt のリスト中に保存されているタイムゾーンを使って解釈し、〈時刻〉を得たものである。ここで tz を指定しないでもよいというのは、年月日時分秒のデータもタイムゾーンのデータも POSIlt じたいの中に含まれているからだ。
ただ、このとき asPOSIXct() の引数として tz= を与えることもできる。そうすると、年月日時分秒は POSIXlt 中に保存されているタイムゾーンではなく、tz= で指定したタイムゾーンが用いられる。
> as.numeric(as.POSIXct(lt)) [1] 15779<b>384</b>55 > as.numeric(as.POSIXct(lt, tz="Japan")) [1] 15779<b>384</b>55 > as.numeric(as.POSIXct(lt, tz="Hongkong")) [1] 15779<b>420</b>55
またこのとき、出来上がった POSIXct クラスのオブジェクトには tz= で指定したタイムゾーンを密かに属性として保存され、これは print.PISIXct() 関数が表示する内容に影響を及ぼす。
現在の時刻は Sys.time() 関数により、POSIXct クラスのオブジェクトとして得ることができる。
> Sys.time() [1] "2019-02-25 08:46:56 JST" > now <- Sys.time() > typeof(now) [1] "double" > as.numeric(now) [1] 1551052044
as.POSIXct() を使って作成した場合と違い、こうして得たオブジェクトは tzone 属性を持っていない。
> attributes(now) $class [1] "POSIXct" "POSIXt"
日付だけを保管するためのクラスに Date クラスがある。
力尽きてきたから ?Date を見て。
S4 クラスは S3 クラスより新しい仕様で、S3 クラスが非公式クラスと言われるのに対して公式のクラスと呼ばれることがある。S4 クラスを使うには、まずクラスを定義してからインスタンスを作成するという手順をとる。
自前でクラスを作成してみよう。
S4 クラスのインスタンスは、スロットと呼ばれるデータを入れるための構造を持っている。これは、名前とオブジェクトのペアの集合体である。クラスを定義するときに、スロット名と、そのスロットに入れるデータのクラスを指定する。さしあたり問題になるのは double 型は基本的に numeric クラスなので、下の age というスロットに指定するのは "numeric" でなくてはならないということだ。
> Girl <- setClass("Girl",
slots = list(name = "character",age="numeric"))
> Boy <- setClass("Boy",
slots = list(name = "character",age="numeric"))
第一引数はクラス名である。S4 クラスのクラス名は最初を大文字にするのが慣習(だそうです)。
setClass 関数の戻り値は、このクラスのコンストラクタ(インスタンスを作成する"closure" 型の関数)である。このコンストラクタの名前はクラス名と同じものにする慣習がある。
では、クラス定義はどこに保管されるかというと、環境(environment)に保管される。
> ls.str(environment(), all.names=TRUE) .__C__Boy : Formal class 'classRepresentation' [package "methods"] with 11 slots .__C__Girl : Formal class 'classRepresentation' [package "methods"] with 11 slots
クラス名からを定義を知るには getClass 関数を使う
> getClass("Girl")
Class "Girl" [in ".GlobalEnv"]
Slots:
Name: name age
Class: character numeric
インスタンスを作成するには、クラス定義のときに作成されたコンストラクタ使って次のようにすればよい。
> sazae <- Girl(name="Sazae", age=24) > masuo <- Boy(name="Masuo", age=28)
同じことを、専用コンストラクタを使わずに行うこともできる。
> sazae <- new("Girl", name="Sazae", age=24)
> masuo <- new("Boy", name="Masuo", age=28)
いま作った 2 つのインスタンスの中身を確認してみる。
> sazae An object of class "Girl" Slot "name": [1] "Sazae" Slot "age": [1] 24 > masuo An object of class "Boy" Slot "name": [1] "Masuo" Slot "age": [1] 28
class 属性は自動的にセットされているから、
> is.object(sazae) [1] TRUE
である。
S3 オブジェクトであるか S4 オブジェクトであるかは、
> isS4(sazae) [1] TRUE
のようにして調べられる。
インスタンスからスロットの中身だけを知るには、次のようにする。
> sazae@age [1] 24 # または > slot(sazae, "age") [1] 24
ジェネリック関数を作成するという点では、S3 クラスのときと同様である。
> setGeneric("respect",
function(x) {
standardGeneric("respect")
})
S4 の standardGeneric() は S3 の UseMethod() に当たるものである。
次にクラスごとに、実際に処理を受け持つ関数をセットする。
> setMethod("respect", c(x="Girl"),
function(x) { paste(x@name, "san") })
> setMethod("respect", c(x="Boy"),
function(x) { paste(x@name, "kun") })
では、前に作ったインスタンスを、ジェネリック関数に与えてみる。
> respect(sazae) [1] "Sazae san" > respect(masuo) [1] "Masuo kun"
ジェネリック関数を作るにはもう一つ方法がある。既存の関数をジェネリック関数に変えてしまうというやり方だ。
では、文字数を数える nchar という関数は、char 型にしか使えないが Girl クラスのオブジェクトに対しても使えるようにしてみる。まず、nchar 関数をジェネリック関数に変える。
> setGeneric("nchar")
[1] "nchar"
あとは、メソッドの作成(1) と同様である。
> setMethod("nchar", c(x="Girl"),
function(x) { nchar(x@name) })
> nchar(sazae)
[1] 5
先に作った Boy クラス
> Boy <- setClass("Boy",
slots = list(name = "character",age="numeric"))
を継承する SchoolBoy クラスを作成してみる。そのために contains に親クラスを指定する。
> SchoolBoy <- setClass("SchoolBoy",
slots = c(grade = "numeric"),
contains = "Boy")
続いてインスタンスを作成。
> katsuo <- SchoolBoy(name="Katsuo", age=11, grade=5)
親クラスのメソッドを使ってみる。
> respect(katsuo) [1] "Katsuo kun"
SchoolBoy クラスの場合は、別扱いとしてみる。
> setMethod("respect", c(x="SchoolBoy"),
function(x) { paste(x@name, "kun", "(grade", x@grade, ")") })
[1] "respect"
> respect(katsuo)
[1] "Katsuo kun (grade 5 )"
文字と数字が混ざったようなデータがあったとする。
> system("cat test.txt")
Masuo Fuguta 28
Anago 27
Masuo と Fuguta の間はスペース、名前と年齢の間はタブになっている。すべてをテキストとして読み込むには、
> scan(file="test.txt", what="", sep="\t") Read 4 items [1] "Masuo Fuguta" "28" "Anago" "27"
である。what には、「このオブジェクトを見本にして、読み込んでね」ということを示すためのオブジェクトを指定する。だから、scan(file="test.txt", what="Hello world!") でも scan(file="test.txt", what="") でも同じことである。簡単に scan("test.txt", "") とも書ける。第二引数を省略するとデフォルトの実数として読み込もうとする。
sep(セパレータ)のデフォルトは「タブまたは空白文字」。ここではタブだけを区切り記号にしたいから明示的に指定している。
もし、上のファイルの 28 や 27 を文字列でなく数として読み込みたいのなら、what にリストを指定して、
> employee <- scan(file="test.txt", what=list(name="", age=0), sep="\t") Read 2 records $name [1] "Masuo Fuguta" "Anago" $age [1] 28 27
のようにする。
read.table は、データを見分けて適切な型を選択した上で、全体を data.frame クラスのオブジェクトにまとめる。このとき、デフォルトでは文字列データは factor 型になる。
> employee_f <- read.table("test.txt", col.names=c("name", "age"), sep="\t")
name age
1 Masuo Fuguta 28
2 Anago 27
> typeof(employee_f)
[1] "list"
> class(employee_f)
[1] "data.frame"
> class(employee_f$name)
[1] "factor"
R で基本的な作図を行うための関数やら何やらは graphics パッケージに入っていて、これは標準で読み込まれる。
以下ではまずデバイスや作図フレームといった言葉が出てくるが、これらも R のオブジェクトではない。われわれは C で書かれたライブラリに定義された関数を通じてこれらの扱いができるだけで、デバイスとかフレームとかいうモノがどこかにあると考えてプログラミングしようね、という話である。もちろん、図を作っている点や線やテキスト、図そのものも R のオブジェクトではない。それらは作図関数と呼ばれる関数たちの副作用として作られるものにすぎない。
作図をするには、まずデバイスを選ぶ必要がある。これは plot() などの高水準作図関数はこれを暗黙のうちにやってくれるので、ふだん意識されないが、図を jpeg や svg や pdf の形でファイルへ書き出したりするためには必要な知識だ。なお、ここでデバイスというのは物理的なものを指すわけもないし、ある特定のフォーマットでの出力に関わる「仕組み」のことである。
標準では pdf, postscript, xfig, bitmap, pictex を選ぶことができ、コンパイル時に指定によって X11, cairo_pdf, cairo_ps, svg, png, jpeg, bmp, tiff, quartz からも選べるようになる。たいがいの環境ではどれも使えるのではないかと思う。
たとえば、私のところでは画面上にウィンドウを開いて図を描く場合、
> X11()
のようにすればデバイスに X11 が選ばれる。svg ならば、書き出すファイル名を引数として
> svg("figure1.svg")
のようにすれば OK だ。
デバイスは複数開くことができ、整数のデバイス番号が 2, 3, 4... と 2 から順番についていく(1 は使われない)。このとき、たとえば X11 デバイスを複数開くというようなこともでき、この場合はそれぞれの X11 デバイスに異なる番号が与えられる。現在選択されているデバイスをカレント・デバイスという。
> dev.cur() svg 3
のようにすると、カレント・デバイスの種類と番号を知ることができる。開いているすべてのデバイスは
> dev.list()
X11cairo svg
2 3
でリストされる。もし複数のデバイスを開いているなら、
> dev.set(2)
X11cairo
2
のようにしてカレント・デバイスを切り替えることができる。使い終わったデバイスは、
> dev.off(3)
X11cairo
2
のようにして閉じることができる。このとき表示されるデバイス番号は、デバイスを閉じたことによりあらたにカレント・デバイスになったデバイスの番号だ。
引数なしで dev.off() とすると、現在のデバイスが閉じられる。jpeg や svg といったファイルに書き込むようなデバイスは、そのデバイスを閉じるまで実際の書き込みは行われない。
デバイスが選ばれていないときに暗黙のうちにデバイスを開く関数が多くあるが(plot() はその一つだ)、その場合はデフォルトのデバイスが用いられる。私のところでは、デフォルトのデバイスは X11 である。
次はデバイス関連の関数だが、dev.copy() については後述する。
デバイス上に作図フレームをつくり、その上に図を描く。作図フレームはいわばリアル世界で図を作成するときの紙のようなものであり、これを用意しなければ作図ができない。
> plot.new()
を行うと、現在デバイスに対して新しい作図フレームが作成される。1 つのデバイスは 1 つの作図フレームしか持つことはできない。複数の図を一つのデバイスに対して描いているような場合もこの例外ではない。
作図フレームのコピーについては、あとで述べる。
R の基本的な作図にかんする関数は、その主要な部分が C で書かれている。作図パラメータたちも R のオブジェクトとして保存されるわけではなく、それらにアクセスするには par() という専用の関数を使わなくてはならない。
par() とすると、すべての作図パラメータとその値が列挙される。パラメータ名だけ列挙するには environment(par)$.Pars(あるいは graphics:::.Pars)でよい。これは、パラメータの値が環境(environment)に保存されているということを意味しない。たんに par(やその他の作図関数)のクロージング環境から、作図パラメータの名前を列挙したベクトルにアクセスできるというだけである。
後の調べものに役立てるために、作図関数の初期値を保存しておくことにする。
> par0 <- par()
次は、bg という名前のパラメータ(バックグラウンド色のパラメータである)に "pink" をセットしているところ。
> par(bg="pink")
次は bg という名前のパラメータの値を求めているところ。
> par("bg")
[1] "pink"
bg の他に変更されたパラメータがないかを調べてみよう。作図パラメータの初期値を保存してある par0 リストと、現在の作図パラメータを比較する。
> par1 <- par() # 現在の作図パラメータすべてのリストを保存 > changed <- as.character(par0)!=as.character(par1) # 初期値と現在値を文字列として比べる > names(par0)[changed] # 変更のあったパラメータ名 [1] "bg" > par0[changed] # 変更前のパラメータ値 $bg [1] "transparent" > par1[changed] # 変更後のパラメータ値 $bg [1] "pink"
作図パラメータ bg が "transparent" から "pink" に変更されて、他に変更がないことが確かめられた。
作図パラメータは、デバイスごとに別々に設定される。先ほど例に挙げた par(bg="pink") は、現在のデバイスの bg パラメータの値に "pink" をセットしたものである。次の例は、デバイスを切り替えるとパラメータが変わりうることを実験している。
> X11() # X11 デバイスを作成し
> jpeg() # 続いて jpeg デバイスを作成する
> dev.list() # デバイスをリストしてみる
X11cairo jpeg
2 3
> dev.cur() # カレント・デバイスは...
jpeg
3 #... 3 である
> dev.set(2) # カレント・デバイスを 2 に戻してから
X11cairo
2
> par(bg="blue") # 作図パラメータの bg を "blue" にセットする
> par("bg") # たしかに bg の値は...
[1] "blue" # ... "blue" になっている
> dev.set(3) # カレント・デバイスを 3 に変えて
jpeg
3
> par("bg") # このデバイスでの bg の値を調べると
[1] "transparent" # デフォルトの "transparent" のままである
あらたにデバイスを開いたとき、そのデバイスのための作図パラメータはデフォルトにリセットされる。また、そのデバイス上にあらたなフレームを作成したときにもリセットされる作図パラメータが多い。
したがって、デバイスを選択する前に par() で作図パラメータをセットしても、その後開いたデバイスの作図パラメータには影響がない。また、多くの作図パラメータは、plot.new() の後に設定しないとデフォルト値が用いられることになる。
いろいろと描き込んだ X11 デバイス上の作図フレームを、他のデバイス上にコピーすることもできる。ディスプレイを確認しながら図を組み上げて、出来上がりを jpeg や svg や pdf ファイルとして出力したいような場合にはぜひマスターしたい技である。
> dev.copy(svg, file="test.svg") svg 4
とすると、test.svg ファイルに関連づけられた svg デバイス——この例の場合はデバイス番号が 4 である——に現在のデバイス上の作図フレームがコピーされ、新しいデバイスがカレント・デバイスになる。
svg デバイスを閉じると、test.svg にファイルに作図フレームの内容が書き込まれる。
> dev.off(4)
X11cairo
2
上の例では新規にデバイスを作成し、そのデバイス上に作図フレームをコピーした。これに対して、すでに存在するデバイス上にカレント・デバイス上の作図フレームをコピーするには、dev.copy(which=コピー先のデバイス番号) とする。
dev.copy() によって、カレント・デバイス上の作図フレームを他のデバイス上にコピーすると、作図パラメータもいっしょに、コピー元のデバイスからコピー先のデバイスにコピーされる。
> dev.list() # デバイスが 2 つあったとする
X11cairo jpeg
2 3
> dev.set(2) # カレント・デバイスを 2 にしてから
X11cairo
2
> par(bg="blue") # 作図パラメータの bg を "blue" にセットする
> dev.set(3) # カレント・デバイスを 3 に変える
jpeg
3
> par("bg") # このデバイスでの bg はデフォルトの "transparent" のままである
[1] "transparent"
> dev.set(2) # 再びカレント・デバイスを 2 にしてから
X11cairo
2
> dev.copy(which=3) # カレント・デバイスのデータフレームをデバイス3 上にコピーする
jpeg
3
> dev.set(3) # カレント・デバイスを 3 にして
jpeg
3
> par("bg") # bg の値を調べると、デバイス 2 からこの値もコピーされている
[1] "blue"
デバイスのサイズがコピーされるかどうかは、どの種類のデバイスからどの種類のデバイスへコピーするかによって異なるので、デバイス・サイズを変更している場合は注意が必要だ。
蛇足ながら、ファイルに出力するようなデバイスは、デバイスを閉じるまで実際の書き込みが行われない。
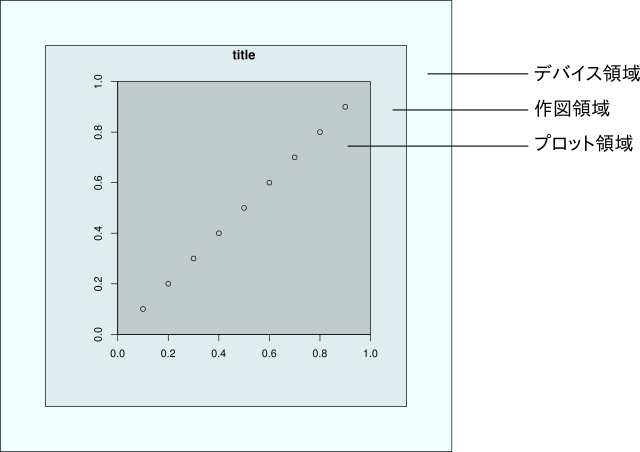
R で作図をするときは、3 つの領域(range)のことを考える必要がある。デバイス領域、作図領域、プロット領域である。デバイス領域はデバイスを開いたときに作られ、作図領域とプロット領域は作図フレームを開いたときに作られる。プロット領域に対してユーザー座標系を設定し、そこに図形やテキスト、散布図において各サンプルを表す点々たち、などなどを配置できる。座標軸やタイトルは、作図領域の内側ならプロット領域の外に描くことができる。
注 一応これが原則だが、(少なくとも私の環境では)points() や text() などが描く図形やテキストがプロット領域から(それどころか作画領域から)はみ出して配置されることがある。しかし、こうしたはみ出した部分は、axis() や box() を使うと、それらと共存できずに見えなくなるので、アテにしてはいけないと思う。
これらの領域のサイズを指定するためにどうしたらいいのかを見ていくことにする。
たとえば
> X11()
のようにしてデバイスを用意すると、デバイス領域が作られ、その大きさは dev.size() によって得られる(デフォルトの表示単位はインチ)。デバイス領域の大きさは、X11() や jpeg() といった関数を実行するときに、オプションとして明示的に与えることができる。X11 デバイスの場合は、マウスで作画ウィンドウのサイズを変更すると、dev.size() の値はそれに追従して変化する。

ここで
> plot.new()
のようにして作図フレームを用意すると、作図パラメータの din が dev.size() に追従して同じ値を保つようになる。

作図フレームを用意したとき作図領域が作成される。作図領域とデバイス領域の関係は、作図パラメータの fig によって決まり、作図領域のサイズは作図パラメータの fin によって決まる。fig と fin の値の間に矛盾がある場合は、自動的に調整される。初期値では fin は c(0,1,0,1) に設定されていて、デバイス領域と作図領域が一致している。
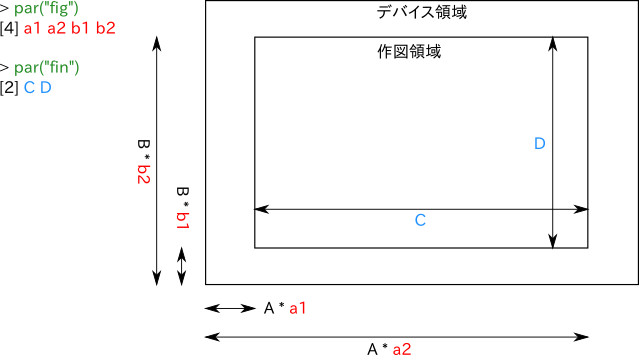
複数の図を一つの作図フレームに複数の図を描いている例をしばしば目にするが、これは一つの図を描き終えると、べつの場所に作図領域を移動させて次の図を描くということをやっているのである。
また、プロット領域もこのとき同時に作成される。作図領域とプロット領域の関係は作図パラメータの plt によって決まり、プロット領域のサイズは作図パラメータの pin によって決まる。plt と pin の値の間に矛盾がある場合は、自動的に調整される。
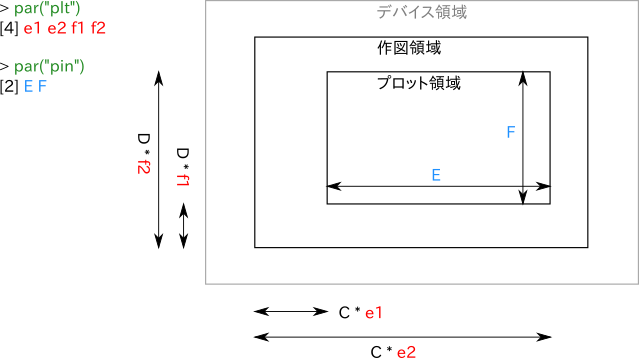
box() コマンドを使うとプロット領域を囲む枠線が描かれるので、これを使ってプロット領域の範囲を確認ができる。
points(), text(), rect() などの低水準作図関数は、現在セットされているユーザー座標系をもとに作図をする。plot() や hist() などの高水準作図関数はユーザー座標系を自動的に変更してから作図する。
par(usr=c(x1,x2,y1,y2)) を行うと、ユーザー座標系による (x1,y1) がプロット領域の左下端に、ユーザー座標系の (x2,y2) がプロット領域の右上端に一致するように作図パラメータ usr が設定される。
さっそく例を見てみよう。
> X11() > par(bg="azure") # デバイス領域(いまは作図領域に等しい)の可視化 > plot.new() > box(col="red") # プロット領域の可視化 > par(usr=c(0, 2, 0, 4)) # プロット領域左下端が (0,0)、右上端が (2,4) になるようにユーザー座標系を決定 > rect(0,0,1,1) # ユーザー座標系で左下(0,0)右上(1,1)となる長方形を描く

上の黒い長方形の横のサイズは、x 方向のユーザーユニットで 1 であり、縦のサイズは y 方向のユーザーユニットで 1 である。つまり、横方向の 1 ユーザーユニットのほうが、縦方向の 1 ユーザーユニットよりも出力したときに長くなっている。これは、ほぼ正方形のプロット領域に対して、par(usr=c(0, 2, 0, 4)) というふうにユーザーユニットを決定したからである。もし、出力したときに x 方向の 1 ユーザーユニットも y 方向の 1 ユーザーユニットも同じ長さになるようにしたいのならば、それなりに考えないといけない。
不便なように見えるかもしれないが、この仕様には便利なところもある。たとえばデバイス領域のサイズを以前よりも小さく変更すると(X11 デバイスでマウスを使ってウィンドウ・サイズを変更したときなどはこの例となる)、それにともない作図領域の大きさが変更され、その結果プロット領域の大きさが変更され、ユーザー座標系の 1 ユニットとリアル世界の 1 インチの関係が x 方向、y 方向で独立して変更される。その結果、ユーザー座標系によって描かれた図の大きさは自動的に伸縮し、図はプロット領域にちょどよくおさまり続ける(縦横比は期待通りでないかもしれないが)。
作図関数とは作図フレームと呼ばれる「紙」に当たるものに対して図形を出力する副作用を持つ関数だ、と一応言ってよいように思う(正確な定義を調べてない)。R のマニュアルに従うと、作図関数は低水準作図関数と高水準作図関数に分かれている。
高水準作図関数がお任せで何もかもやってくれるのに対して、低水準作図関数は単純な仕事しかやらない。しかし、とくに重要な違いは、高水準作図関数がデバイスやフレームを暗黙のうちに用意するのに対して、低水準作図関数はそれらをやらないということである。
比喩を用いて言うならば、高水準作図関数が、お絵描きをする人に新しい紙を用意してくれるところから始めるのに対して、低水準作図関数はすでに用意されている紙に何か描いてくれるというわけである。そんなわけで、低水準作図関数は高水準作図関数描いた図の修正に使われることが多い。
もちろん「紙」やら何やらを手動で用意すれば、低水準作図関数のみを使って図を作成することができる。そこで、ここでは低水準作図関数だけを用いて作図を試みる。
(1,1),(2,2),...,(10,10) という点を xy 座標にプロットしてみよう。まず、x, y それぞれのデータを用意する。
> x <- c(1:10) > y <- c(1:10)
いまは画面上に描画することにして、デバイスとして X11 を選択する。
> X11()
X11 デバイスが用意され、このデバイスのための作図パラメータはデフォルトにセットされる。われわれはウィンドウ・マネージャが空白のウィンドウが開くのを見る。ここで、
> par(bg="pink")
のようにして、バックグラウンドをピンクにセットしてみる。もし、これに先立ちデバイスの選択を行っていない場合は、暗黙のうちに デフォルトのデバイスが作成されてから、そのデバイスに対して作図パラメータがセットされる。
つづいて、
> plot.new()
のようにして、カレント・デバイス上に作図フレームを用意する。もしまだデバイスが選択されていないなら、この時点で X11() が呼ばれ、その上に新しい作図フレームが用意される。
注 もし、何かを描いた後にまた真っ新な紙を用意して描き直したいのなら、たいがいの場合は再び plot.new() を使えばよい。プロットした結果や、par("usr") (描く範囲)などのパラメータはそれでリセットされる。ただ、par("bg") (バックグラウンド・カラー)などは、明示的に変更するか、デバイスがリセットされるまで従前のものが使われる。
ここでいったん立ち止まるべきだろう。私たちは何をしたいのか? すべてのデータをプロットして、それで図をいっぱいに使いたいのなら、やるべきことはいちばん端っこにあるプロットがちょうどプロット領域の端にくるようにユーザー座標系をうまくセットすることだ。ただし、プロット領域に少しだけ余裕をもたせておかないと、端の点は半分がプロット領域の外に飛び出して、半分しか見えないことになってしまうだろう。
そこで、プロット領域全体をユーザー座標系であらわしたときに x 軸方向に 0 から 11 まであり、y 軸方向に 0.5 から 10.5 まであるようにしよう。
> par(usr=c(0,11,0.5,10.5))
あとは、低水準作図関数の points() を使ってプロットをすればよい。
> points(x,y)
基本的なプロットは、これで終わりである。
図に目盛りを入れるには、低水準作図関数の axis() を用いる。さっそくやってみる。
まずデバイスを選び、作図フレームを作成する。
> X11() > plot.new()
プロット領域にデフォルトで設定されたユーザー座標系を調べて、x 軸方向の最小値と最大値、y 軸方向の最小値と最大値を求める。
> par("usr")
[1] -0.04 1.04 -0.04 1.04
このユーザー座標系からすると、x 軸を 0 から 1 まで、y 軸を 0 から 1 まで描くのがよさそうだ。
まず長方形を描く rect() 関数で、プロット領域全体に色をつけておいてから、
> rect(-0.04, -0.04, 1.04, 1.04, col="azure", border=NA)
座標軸を描いてみよう。
axis() 関数の引数 side に 1 を指定すると、プロット領域の下側に、2 を指定すると左側に軸を描くことができる。どちらも 0, 0.1, 0.2...0.9, 1 という目盛りをつけたいので、これを引数 at に与える。
> axis(side=1, at=c(0:10)/10) > axis(side=2, at=c(0:10)/10)

これが低水準作図関数を用いたごく一般的な座標軸の描き方で、座標軸は作図領域の内側でプロット領域の外側になる部分に描かれることになる。
この例では axis の at 引数によって座標軸のどこに目盛りをつけるかを明示的に与えたが、それを省略してお任せで目盛りを刻むことも可能である。
> X11() > plot.new() > rect(-0.04, -0.04, 1.04, 1.04, col="azure", border=NA) > axis(side=1) > axis(side=2)

第一の疑問。目盛りをつける場所はだれがいつ決めたのだろうか。
われわれが作図フレームを作成すると、その上に作図領域とプロット領域がセットされる。そしてプロット領域に対してユーザー座標系がデフォルトに設定されるが、このとき「デフォルトで目盛りをどこに刻むか」が作図パラメータの xaxp と yaxp としてセットされる。axis() は引数 at を省略されたとき、この xaxp と yaxp を参照して目盛りをつけるのである。
現在の xaxp, yaxp の値を見てみよう。
> par("xaxp")
[1] 0 1 5
> par("yaxp")
[1] 0 1 5
どちらもその値は c(0,1,5) になっている。これは、0 から 1 までを 5 つに分けるように目盛りをつけよ、という意味だ。
第二の疑問。われわれが明示的に作図パラメータ usr を与えてユーザー座標系を変更すると、作図パラメータ xaxp, yaxp と齟齬が生じ、目盛りが奇妙な場所についてしまうのではないか。
> par0 <- par() # 現在の作図パラメータのリストを保存してから > par(usr=c(0,10,0,10)) # ユーザー座標系を決定する作図パラメータ usr 変更する > par1 <- par() # あらたな作図パラメータのリストを保存 > changed <- as.character(par0)!=as.character(par1) # パラメータ・リストの変更された要素 > names(par0)[changed] # 変更されたパラメータ名 [1] "cxy" "usr" "xaxp" "yaxp"
明示的に変更したのは usr だけだったが、cxy, xaxp, yaxp も自動的に変更されている。cxy は別のところで考えることにして、いまは xaxp と yaxp の値がどう変わったかを見てみよう。
> par0$xaxp [1] 0 1 5 # usr 変更前 > par1$xaxp [1] 0 10 5 # usr 変更後 > par0$yaxp [1] 0 1 5 # usr 変更前 > par1$yaxp [1] 0 10 5 # usr 変更後
xaxp も yaxp も「0 から 1 までを 5 つに分割する」から「0 から 10 までを 5 つに分割する」に変わっている。つまり、作図パラメータ par を設定してユーザー座標系を変更すると、xaxp と yayp がそれに応じて自動的に変更され、デフォルトの軸目盛りも変わるわけである。
第三の疑問。5 つに分けるというのは、誰がいつ決めたのか。5 つにうまく分けられないときは、これは別の分割数になるのか。
意地悪をして、作図パラメータ usr を x 軸方向、y 軸方向とも 1〜18 に変えて、軸を描いてみよう。幅 17 の区間を 5 つの区間に分けると、分割点の値がキリの悪い数になること請け合いだ。
> plot.new() > par(usr=c(1,18,1,18)) # プロット領域の左下隅が (1,1)、右上隅が (18,18) になるようユーザー座標系を設定 > par()$xaxp [1] 5 15 2 # 5 から 15 までを 2 つの区間に分ける > par()$yaxp [1] 5 15 2 # 5 から 15 までを 2 つの区間に分ける
x 軸 y 軸とも「5 から 15 までを 2 つの区間に分けよ」となった。これでは、目盛りが 1 〜 18 までをカバーしない。それに、これは用向きにもよるが、たぶん幅が 5 という目盛り間隔は荒すぎるだろう。実際、描いてみると、
> axis(side=1) > axis(side=2)
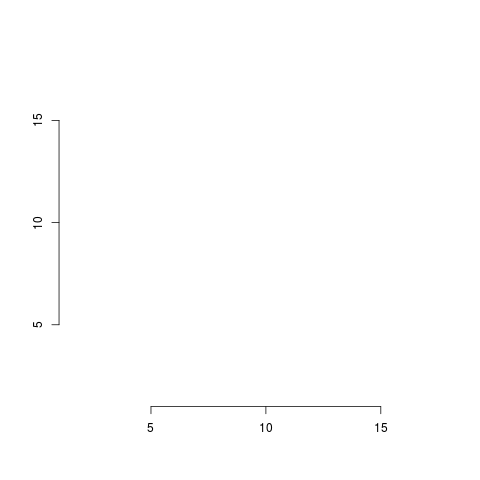
やはりなんだか心許ない目盛りが出力された。(ちなみに、高水準作図関数 plot() を使っても同じような軸が描かれる)。
第四の疑問。usr が変更されたとき、どのようなアルゴリズムで xaxp や yaxp が決定されるのか。それを知るために、われわれは pretty() というかわいらしい名前の関数を調べなくてはならない。
引数として与えられた数ベクトルを含むような範囲を得て、その範囲をいくつかの同じ幅をもつ範囲に分割する。そして両端点を含む分割点のベクトルを返す。このとき、各分割点が人間がが見てキリのいい数になるようにする。この関数は主に座標軸に目盛りをつける場所を決定するのに使われる。この関数は作図パラメータを変更するという副作用を持たない。
この関数は、典型的には数ベクトルを引数にする。
> pretty(c(8,16)) [1] 8 10 12 14 16
他の引数を与えることもできる。n という引数名で、与えられた範囲をいくつに区切るかを指定できる。マニュアルによると、分割数は希望通りになるとは限らない。また、min.n は最低限いくつに区切るかを指定できる。
もちろん、こうしたはわれわれの興味をそそることだ。pretty() はいったいどんな仕組みで分割点を見出しているのだろう。
たとえば、上の例ではどのように計算されているのだろう。「?pretty」を見ると、おおまかなことがわかる。
pretty() はまず引数になった数ベクトルから最小値と最大値を求める。つまり、ここでは 8 と 16 だ。そして、それを 5 つに分割しようとする(この 5 の代わりにオプション引数 n= として与えたお好みの非負整数を使うことができる)。8 から 16 の間を 5 つに等分すると (16-8)/5=1.6 である。しかし、この 1.6 をそのまま目盛りの幅に使うと、
> seq(from=8, to=16, by=1.6) [1] 8.0 9.6 11.2 12.8 14.4 16.0
という、ろくでもなく中途半端な目盛りを刻まなくてはならない。これでは、ぜんぜん pretty とは言えない。そこで pretty() は、...0.01, 0.1, 1, 10, 100... といった 10 のべき乗の中から、1.6 を超えない最大のものを選ぶ。この例では 1 がそれである。あとは「1 の 1 倍」「1 の 2 倍」「1 の 5 倍」「1 の 10 倍」のいずれかを選択して、その倍数の数列をつくる。上の例では「1 の 2 倍」が選択されており、...-2,0,2,4... という数列がつくられる。こうした数列から目盛りの位置を得るのである。ここでは 8 〜 16 を含むひとつながりが抜き出され 8 10 12 14 16 を得ている。なお「1 倍」、「2 倍」、「5 倍」、「10倍」というのは pretty が常に使うあらかじめ決まっている選択肢で、人がキリがいいと感じる数ということのようだ。
では、pretty() は「1 倍」、「2 倍」、「5 倍」、「10倍」の中からひとつを選択するとき何を基準にするのだろう。これについて「?pretty」は語っていない。ただ、2 つの引数を用いて、我々の好みを pretty() に伝える手段があると言っているだけである。すなわち、引数名の high.u.bias と u5.bias である。high.u.bias は非負の、典型的には 1 より大きな数が指定され、この数が大きいほど目盛りは荒くなる。u5.bias は 5 のことが 2 よりどのくらい好きかを伝えるための引数で、デフォルトは 'Optimal' となっているが、これは .5 + 1.5*high.u.bias に等しいという。
これらのオプションが効果を示している例を見ておこう。
> pretty(c(64,128)) [1] 60 70 80 90 100 110 120 130 > pretty(c(64,128), high.u.bias=3) [1] 60 80 100 120 140
> pretty(c(128,256)) [1] 120 140 160 180 200 220 240 260 > pretty(c(128,256), u5.bias=5) [1] 100 150 200 250 300
作図パラメータ usr が変化すると、R は暗黙のうちに作図パラメータxaxp と yaxp をセットし直すが、このとき pretty() 関数が使われる。ただし、xaxp と yaxp は、pretty() が決定した目盛りたちの位置のうち、プロット領域内にあるものだけを用いる。
> pretty(c(1,18)) [1] 0 5 10 15 20 > par(usr=c(1,18,1,18))# プロット領域の左下隅が (1,1)、右上隅が (18,18) になるようユーザー座標系を設定 > par()$xaxp [1] 5 15 2 # 5 から 15 までを 2 つの区間に分ける、の意味 > par()$yaxp [1] 5 15 2 # 5 から 15 までを 2 つの区間に分ける、の意味
上の例では、pretty() が返す数ベクトルのうち、0 と 20 はプロット領域外に位置するので、これらを無視している。
pretty() 関数をうまく用いれば、asix() 関数がつける目盛りを、ある程度楽をしながらそれなりにコントロールすることができる。たとえば、前に作った心許ない座標軸を持つケースについては
> X11() > plot.new() > par(usr=c(1,18,1,18)) > axis(side=1, at=pretty(c(1,18),n=8)) > axis(side=2, at=pretty(c(1,18),n=8))
のようにすると
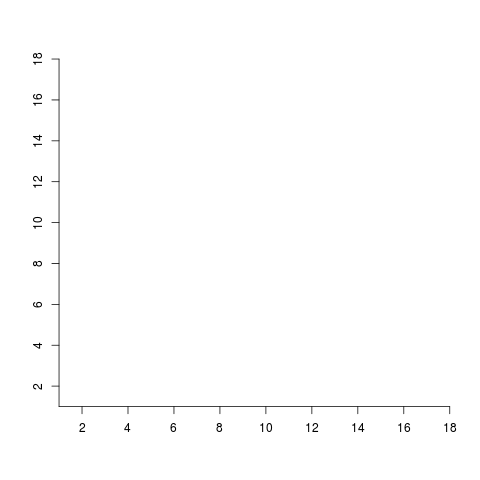
のようになる。
高水準作図関数 hist() でヒストグラムを作るときの階級分けは、まずサンプル数からスタージェスの公式によって階級数を求め、それを n オプションの値として pretty() で階級幅を決定する(たぶん)。
plot.window() は作図パラメータ usr を自動的に設定する関数である。plot() などの高水準作図関数はこれを呼び出してユーザー座標系を決定している。
> plot.new() > xlim <- c(1,10) > ylim <- c(1,10) > log <- "" > asp <- NA > plot.window(xlim, ylim, log, asp)
のようにしてから、par() で "usr" パラメータの値を見てみると、
> par("usr")
[1] 0.64 10.36 0.64 10.36
のように作図範囲を指定する作図パラメータ usr が自動的に決定されていることがわかる。引数 log は "" "x" "y" "xy" のいずれかを引数としてとり、いずれの軸を常用対数にするかを指定する。
では引数 asp は何のためにあるのだろうか。
ここに、
> x <- c(0:10) > y <- c(0:10)*10
というデータがあったとする。これから散布図をつくるとき、われわれはふつうすべてのプロットを打ちたいと思うし、そうして打ったプロットがプロット領域いっぱいに広がっているのが恰好いいと思う。だがときには、x の変動に対して y の変動が大きいということを表現したいこともある。その場合は、x 軸と y 軸のスケールをそろえたいだろう。
そのための計算は、ほんの少しめんどうなところがある。たんに作図パラメータ usr を c(1,100,1,100) すればいいというものではない。それで済むのは、プロット領域の縦横比がちょうど 1:1 になっているときだけである。
plot.window() 関数は、手で計算する代りに自動的にこれを実現する手段となる。つまり、プロット領域の縦横比も考慮に入れたうえで、x 軸と y 軸のスケールを等しくするには、asp=1 にすればよい。実際にやってみよう。
> x <- c(0:10)
> y <- c(0:10)*10
> X11()
> plot.new()
> par("pin") # プロット領域の大きさを調べると
[1] 5.755698 5.149583 # ほぼ正方形だった
> par(pin=c(5,2.5)) # それを横長にして
> box() # プロット領域の形を見てみる
> plot.window(range(x), range(y), log="", asp=1) # 縦横同じスケールで
> points(x,y) # 散布図を描いてみる
> axis(side=1)
> axis(side=2)
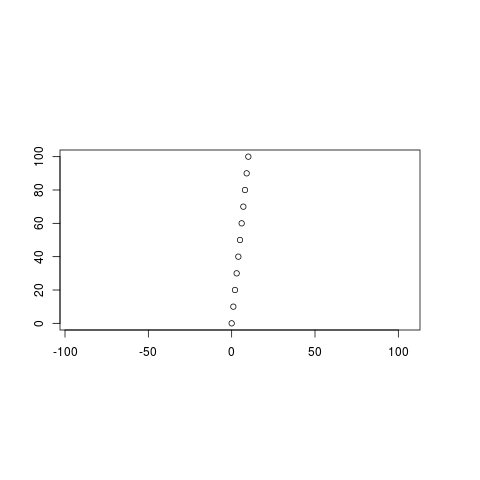
ついでだから、手作りできれいな円を描いてみよう。
> t=seq(from=0, to=2*pi, by=pi/100) > X11() > plot.new() > plot.window(range(cos(t)), range(sin(t)), log="", asp=1) > points(cos(t),sin(t),type="l")

asp に 1 以外の数を与えた場合の効果も見ておこう。
> t=seq(from=0, to=2*pi, by=pi/100) > X11() > plot.new() > plot.window(range(cos(t)), range(sin(t)), log="", asp=0.5) > points(cos(t),sin(t),type="l")
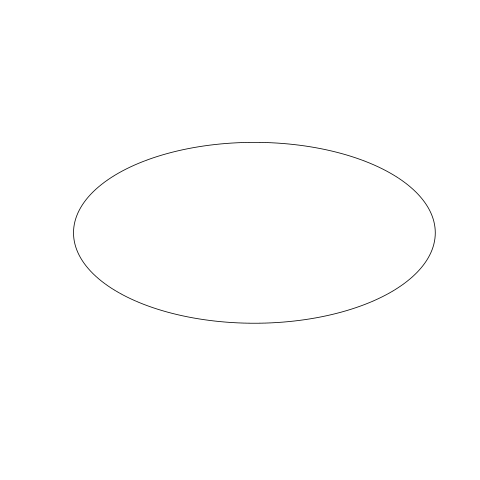
高水準作図関数と低水準作図関数の大きな違いは、前者が暗黙のうちに作図フレームを新規に作成するところにある。その結果、デバイスに対していままで出力された図などはクリアされ、作図パラメータもほとんどがリセットされる。したがって、高水準作図関数の作った図を、別の高水準作図関数が作った図に重ねるというようなことはできない。一つ目の高水準関数で描画した内容は、二つ目の高水準関数が呼び出す plot.new() によって消されてしまうからだ。高水準作図関数で描いた図の修正には、低水準作図関数を使わなくてはならないのもこのためだ。
plot() は generic 関数で、引数のクラスに応じて plot.default() をはじめとした関数に処理を任せる。これらの plot 族の高水準作図関数は、いろいろお任せで作図してくれる。
たとえば、
> x <- c(1:10) > y <- c(1:10) > plot.default(x,y)
とするだけで、かなり豪華な散布図を作成してくれる。
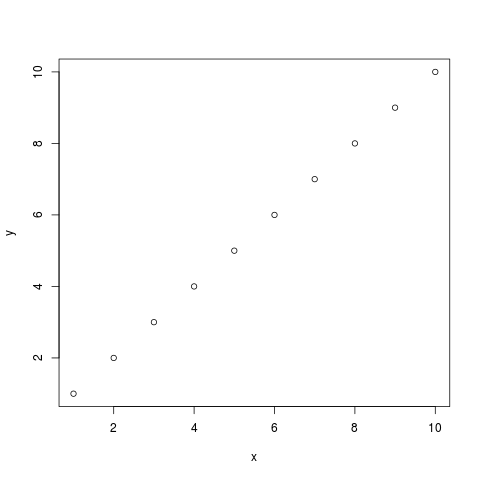
もし、これに他のデータのプロットを重ね書きしたいのなら、続けて
> points(x,11-y)
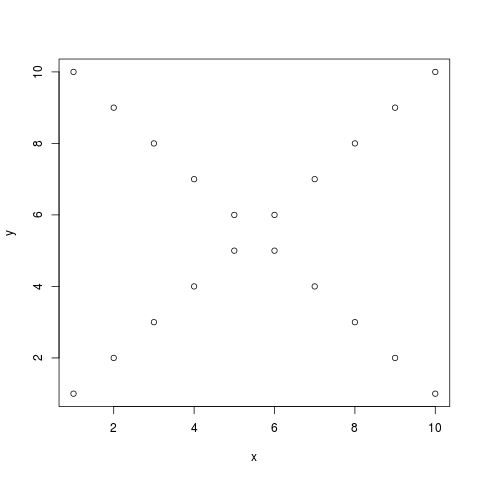
のように、低水準作図関数を用いればよい。
> n <- rnorm(100)
で発生させたサンプルをヒストグラムで表現してみる。(rnorm(N) はデフォルトでは平均0、標準偏差1の正規分布をする母集団からランダムに N 個のサンプルを得る)
> hist(n)
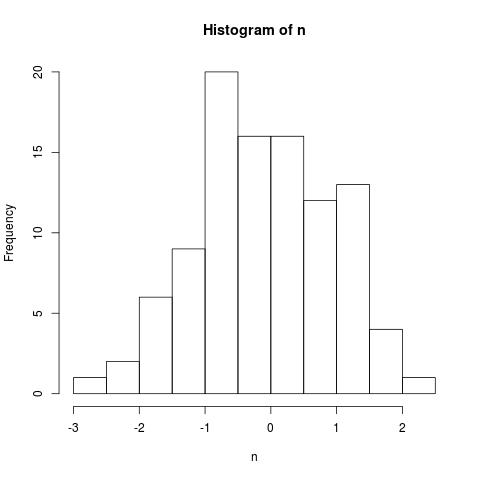
ここでいつも問題になるのは、階級分けをどうするかということだ。hist() は階級を分ける点を指定する方法をオプション breaks= として与えることができ、デフォルトでは breaks = "Sturges"になっている。スタージェスの公式というやつで、「1+log(2)(サンプル数)」だ。
R は breaks が "Sturges" だと、nclass.Sturges() を呼び出して使う。サンプルをおさめた数ベクトル n に対して手動でこの関数を実行してみると、
> nclass.Sturges(n) [1] 8
のようになった。階級数は 8 のはずである。しかし、上で見た通り、hist(n) は階級を 11 に分けている。これはどういうことか。どうやら、各階級の境目の値をキリのいい数にした結果らしい。
いくらか明示的なやり方で同様のことを再現してみる。サンプルのベクトルと Sturgess の公式で得た階級数を pretty に与えて、その結果得た階級の境目の値のベクトルをもとに、ヒストグラムを描いてみると、次のようになる。(hist() 関数では x 軸を描かずに、それは別途 axis で描いている)
> m <- pretty(n, nclass.Sturges(n)) > m [1] -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0 2.5 > hist(n, breaks=m, axes=FALSE) > axis(side=1, at=m)
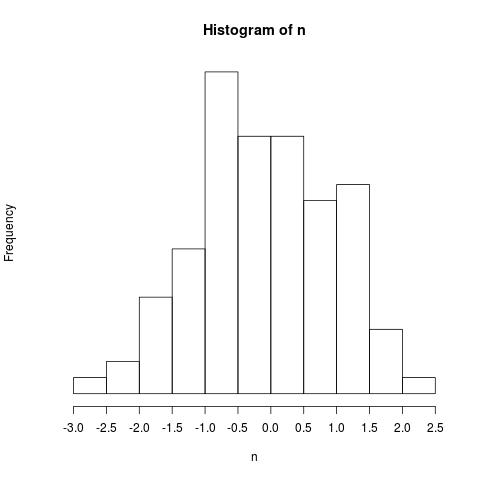
ちなみに、hist() のオプショナルな引数名は axes で、軸を描く関数名は axis である。axis /ǽksəs/ の複数形が axes /ǽksiːz/ なのだが、ちょっと間違えやすい。
まったくの蛇足ながら、同じサンプルを枝葉図(stem-and-leaf plot)で表現してみる。
> stem(n) The decimal point is at the | -2 | 6 -2 | 20 -1 | 9765555 -1 | 442111100 -0 | 99999888888776666555555 -0 | 443322111110 0 | 001111111223444 0 | 5555666778999 1 | 0001112233444 1 | 6778 2 | 0
人は円グラフにだまされやすいという話がある。R のドキュメントでは、
Pie charts are a very bad way of displaying information. The eye is good at judging linear measures and bad at judging relative areas. A bar chart or dot chart is a preferable way of displaying this type of data. (円グラフは情報を表示するのにはとても悪い方法だ。目は直線の長さを判断するのは得意だが、相対的なめんせきを判断するのは不得意なのだ。このタイプのデータを表示するのには、バー・チャートまたはドット・チャートがより好ましい。)
のように述べているくらいである。それはともかくとして、一般的には円グラフはプレゼンなどで好まれているようだから、ひとつ R における作り方を見ておくことにする。
a が 3 で、b が 2、c が 1 というデータがあるとして、円グラフを高水準作図関数の pie() で作成してみる。
> pie(c(a=3,b=2,c=1), clockwise=TRUE, angle=0)

pie() のデフォルトでは 3 時の方向からはじめて左回りに進むが、上の例では clockwise, と angle に値を与え、 12 時の方向から右回りにしている。
R を対話的に使っていて、
> a <- 1
のように、"a" に 1 をバインドしても、実行結果は表示されない。しかしながら、それは見ることができないだけで、オブジェクトが返されている。だから
a <- b <- 1
とすると、b に 1 がバインドされて、見えない 1 が返され、これが a にバインドされる。結局 a も b も 1 にバインドされる。
この見えないオブジェクトを見るためには、
> (a <- 1) [1] 1
のようにするといい。
まず、いくらか細かいことを調べるときのために、 https://cran.r-project.org/web/packages/pryr/index.html にある pryr: Tools for Computing on the Language (Useful tools to pry back the covers of R and understand the language at a deeper level.) をインストールしておく。
> install.packages("pryr")
== はもとより、identical() もメモリ上の同じ場所に保管されている同じオブジェクトだということを調べるものではない。
> x <- 1 > y <- 1 > x == y [1] TRUE > identical(x,y) [1] TRUE
別々に作成した x や y が指すオブジェクトが別の場所に保管されているというのを見る。
> pryr::address(x) [1] "0x2bbd088" > pryr::address(y) [1] "0x2bbd0e8"
次の場合は、y が「x が指すモノ」を指すようになるが、この場合は、x も y もメモリ上の同じところにあるモノを指している。
> x<-1 > y<-x > pryr::address(x) [1] "0x2de6098" > pryr::address(y) [1] "0x2de6098"
> x <- 1
のようにするとき、<- の左にある x はシンボルまたは名前と呼ばれるオブジェクトである。このような場所にあるときを除けば、x と書いたものは x が指す別のオブジェクトに置き換えられる。
シンボルそのものを得るには
> quote(x) x > typeof(quote(x)) [1] "symbol"
このシンボル x を評価すると、1 が得られる。
> eval(quote(x)) [1] 1
substitute() は quote() の仲間だが、少し違いがある。
Rscript というラッパーを使うと楽。たとえば、123+456+789 を出力するには、シェルから
$ echo 123 456 789 | Rscript -e 'x<-scan(file="stdin", what=0); cat(sum(x)); cat("\n")' 2>/dev/null
1368
みたいな感じで。
print() を使うと [1] 1368 みたいな人間用の出力になるから、cat() を使う。おしまいの改行とかは入らないから自前で手当。
もう少し複雑なことは、スクリプトをファイルに書いたりすると楽。次は、標準入力から得たデータをもとに円グラフの svg を作り、コマンドライン引数で与えたファイル名に書き込んでいる。なお、デバイスは自動的に閉じられる。
$ cat pie.r a <- scan(file="stdin", what="") la <- a[c(T,F)] x <- a[c(F,T)] svg(commandArgs(trailingOnly=TRUE)[1]) pie(as.numeric(x),labels=la) $ echo "a 10 b 20 c 30" | Rscript pie.r "pie.svg" Read 6 items
commandArgs() 関数は、コマンドライン引数を取得する。ここでは、pie.svg というファイル名をコマンドラインから与えて、その名前で svg デバイスを開いている。
