
2015-5-19(Tue)改訂
コンピュータで扱いやすい訓点(返り点等)の規格を考えてみる。マークアップした原文を機械的に処理することで、読み下し文が出力できるようにしたい。アイディアは簡単で、グループ化と交換を繰り返せば、文字をどのような順序で読ませることも可能だというものだ。なお、人間による可読性を重視して、できるだけマークアップに使うバイト数を少なくすることを心掛けた。その結果、かなり直感的にわかるものになったと思う。
最初に規則を挙げ、次にマーク・アップの例を示す。最後に sed と JavaScript で簡単な実装を行う。これらのプログラムはマークアップされたテキストを、「読み下し文」および「原文」として出力する。
このマークアップ方式に名前がないのも不便であるから、YKML(読み下しマークアップ言語)という名前をつけておくw。
文は一つの要素からなる。
要素は 「文字」「( ) による表現」「[ ] による表現」をデリミタをはさまずに並べて作られる。

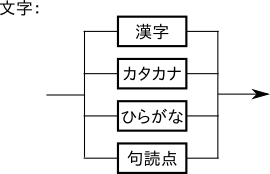
文字は、漢字、ひらがな、カタカナ、句読点のいずれかである。
() による表現は、(要素1 要素2) からなり、要素の間にはホワイトスペースがデリミタとして置かれる。インタープリタは第2要素を出力した後、第1要素を出力する。

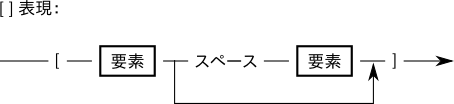
[ ] による表現は、[要素1 要素2] または [要素1] の形をとり、要素が 2 個ある場合にはホワイトスペースがデリミタとして置かれる。インタープリタは 2 番目の要素のみを出力する。要素が 1 個しかない場合、何も出力しない。
dup は他のマークアップが解析されるのに先立って実行される命令で、それ以前に読み込んだ漢字のうち最後の一文字をその場所にコピーする。(再読文字のために用意された命令である)
※そのうち、ルビをふる方法を追加しようと思っている
山高シ → 山高シ
(有リ 朋) → 朋有リ
([不 ズ] 知ラ) → 知ラズ
(以テ 吾(従フヲ 大夫[之 の]後ニ)) → 吾大夫ノ後ニ従フヲ以テ
([不 ザ]ル 敢テ([不 ズ]ンバアラ 告ゲ))也 → 敢テ告ゲズンバアラザル也
天将ニ([dup ス] (以テ 夫子ヲ)(為サント 木鐸ト))
→天将ニ夫子ヲ以テ木鐸ト為サントス
マークアップしたもの
陳成子(弑セリ 簡公ヲ)。孔子沐浴シテ朝シ、(告ゲテ [於]哀公ニ)曰ク。陳恒(弑セリ 其ノ君ヲ)。請フ(討タン 之ヲ)。公曰ク、(告ゲヨ 夫ノ三子ニ)。孔子曰ク、(以テ 吾(從フヲ 大夫[之 ノ]後ニ))、([不 ザ]ル 敢ヘテ([不 ズ]ンバアラ 告ゲ))也。
読み下し出力した結果
陳成子簡公ヲ弑セリ。孔子沐浴シテ朝シ、哀公ニ告ゲテ曰ク。陳恒其ノ君ヲ弑セリ。 請フ之ヲ討タン。公曰ク、夫ノ三子ニ告ゲヨ。孔子曰ク、吾大夫ノ後ニ從フヲ以テ、 敢ヘテ告ゲズンバアラザル也。
原文出力した結果
陳成子弑簡公。孔子沐浴朝、告於哀公曰。陳恒弑其君。請討之。公曰、告夫三子。孔子曰、以吾從大夫之後、不敢不告也。
マークアップしたもの。
外史氏曰ク。我(讀ミテ 舊志ヲ)。(見ル 鳥羽帝ノ時、數(下シ 制符ヲ)。(禁ズルヲ 諸州ノ武士ノ(屬スルヲ 源平二氏ニ)))。曰ク。「大權[之 ノ](歸スル 将門ニ)[ヤ 也]。其レ(在ル [於]此ノ時ニ)[歟 カ]ト」。(及ビ (讀ムニ 三善清行ノ封事ニ(陳ベルヲ 宿衛豪横[之 ノ]患ヲ)))、乃チ知ル制度[之 ノ]弊、其ノ來ルコト久シ[矣]。
読み下し出力したもの。
外史氏曰ク。我舊志ヲ讀ミテ。鳥羽帝ノ時、數制符ヲ下シ。諸州ノ武士ノ源平二氏ニ屬スルヲ禁ズルヲ見ル。曰ク。「大權ノ将門ニ歸スル也。其レ此ノ時ニ在ルカト」。三善清行ノ封事ニ宿衛豪横ノ患ヲ陳ベルヲ讀ムニ及ビ、乃チ知ル制度ノ弊、其ノ來ルコト久シ。
原文出力したもの。
外史氏曰。我讀舊志。見鳥羽帝時、數下制符。禁諸州武士屬源平二氏。曰。「大權之歸将門也。其在於此時歟」。及讀三善清行封事陳宿衛豪横之患、乃知制度之弊、其來久矣
#!/bin/sed s/\([^][ ()あ-んア-ン、。]\)\([][ ()あ-んア-ン、。]*\)dup/\1\2\1/g :a s/\[\([^][ ][^][ ]*\) *\([^][ ]*\)\]/\2/g ta :b s/(\([^ ()][^ ()]*\) \([^ ()][^ ()]*\))/\2\1/g tb
#!bin/sed s/dup//g s/[][() あ-んア-ン][][() あ-んア-ン]*//g
なお、上で使った JavaScript の主要部分は次の通り。
<script>
var m1 = /([^\]\[ ()あ-んア-ン、。])([\]\[ ()あ-んア-ン、。]*)dup/g;
var s1 = "$1$2$1";
var m2 = /\[([^\]\[ ][^\]\[ ]*) *([^\]\[ ]*)\]/g
var s2 = "$2"
var m3 = /\(([^ \(\)][^ \(\)]*) ([^ \(\)][^ \(\)]*)\)/g
var s3 = "$2$1"
var m4 = /dup|[\]\[\(\) あ-んア-ン][\]\[\(\) あ-んア-ン]*/g
var s4 = ""
function yomikudasu(text) {
text = text.replace(m1, s1);
while (text.search(m2) >= 0) { text = text.replace(m2, s2); }
while (text.search(m3) >= 0) { text = text.replace(m3, s3); }
return text;
}
function genbun(text) {
return text.replace(m4, s4);
}
</script>
同じ原文から同じ読み下し文を得るために、違ったマークアップが考えられる。
ABC を CBA の順で読み下す場合、((A B) C) とすることもできるし (A (B C)) とすることもできる。これは、文法的に A B | C と切るべきか、A | B C と切るべきかによればいいだろう。
また、([不 ズ] 知ラ) を ([不]ズ 知ラ) と記しても同じ結果となる。不をズと読むということが示せるので、前者のほうが好ましいと思う。
おわり

返り点の再発明(テキスト書類用) by kabipanotoko is licensed under a Creative Commons Attribution 4.0 International License.
Based on a work at http://www.kabipan.com/language/japanese/yomikudashi.html.
※ちなみに、上のライセンスは、規格の説明についてのもので、規格自体にはそもそも著作権が存在しないと思いますので、ご自由に使って下さい。というか、面白いから使ってみて